




DynamoDB is a fully managed NoSQL database capable of handling any scale. It also offers outstanding features for native integration with other services. As it is not your typical NoSQL storage and possesses a long list of unique aspects, understanding its inner workings is essential - not only for grasping its pricing structure but also for utilizing it effectively.
In this article, we'll delve into all the factors that impact your monthly expenses for DynamoDB. We'll also examine the essential aspects to consider for optimizing DynamoDB usage according to your needs while keeping costs as minimal as possible.
Amazon DynamoDB Infographic
In our opinion, DynamoDB is one of the best services offered by AWS. That's why we've compiled the most crucial facts about this service into an infographic. Feel free to take a look at it before continuing with this article.

Introduction
Before delving into the pricing details, it is crucial to comprehend how DynamoDB functions internally, as the pricing structure is closely intertwined with the actual usage of the service.
DynamoDB - Amazon's Flagship Database Service
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. It is designed to be highly available, durable, and secure, making it a popular choice for building web, mobile, IoT, and many other applications.
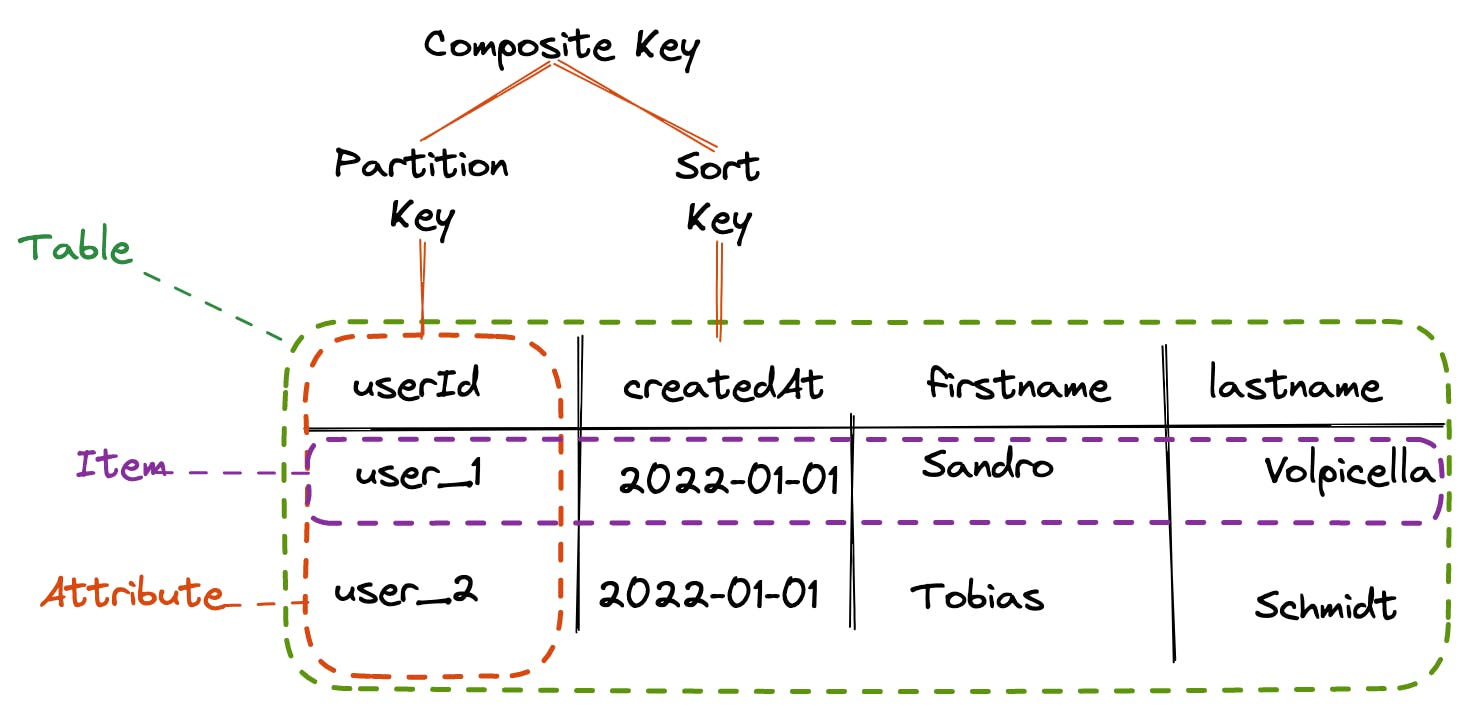
Partitions and Hash Keys
DynamoDB internally saves items into different partitions based on the partition key, also known as the hash key.
The hash key is used to determine the partition where an item is stored. DynamoDB uses a hash function to distribute items across partitions evenly. Each partition has a maximum size limit of 10 GB, and DynamoDB automatically splits partitions that exceed this limit into multiple partitions.
Range Keys
In addition to the hash key, DynamoDB also supports a range key, also known as the sort key. The range key is used to sort items within a partition. When you create a table, you specify can either specify a hash key or hash key and range key. In the latter case, the primary key (which needs to be unique) is a combination of the hash and range key.
The combination of hash and range keys provides a powerful way to organize and query data in DynamoDB. You can use the hash key to quickly locate the partition where an item is stored, and then use the range key to retrieve a specific item or a range of items within the partition. You can also perform queries that filter items based on specific attribute values or use indexes to query data differently.
Retrieving Data
When using the query operation to retrieve items, you must always specify the hash key. If your table includes a range key, you can apply a comparator (e.g., equals, less than, or greater than) to the range key.
Alternatively, you can utilize the scan method, where DynamoDB will iterate through your data and return items that correspond to your specified filter. However, this approach is highly inefficient, time-consuming, and expensive. Compared to query operations, you will be charged for every item scanned rather than only for the items returned.
Capacity Modes
DynamoDB offers two capacity modes for read/write operations: on-demand and provisioned:
On-demand capacity mode charges you for the actual read capacity units (RCUs) and write capacity units (WCUs) consumed by your application requests
Provisioned capacity mode requires you to specify the number of RCUs/WCUs you need and charges you for them even if you don't fully utilize them.
DynamoDB also offers automatic backups, point-in-time recovery, and global tables for multi-region replication.
Additionally, DynamoDB natively integrates with other AWS services like Amazon Kinesis, AWS Lambda, and Amazon CloudWatch for enhanced functionality.
The most prominent paper for DynamoDB goes back to 2007 and is worth a read, even if you're not a data scientist or interested in algorithms: Dynamo - Amazon’s Highly Available Key-value Store.
Why It Is Crucial to Comprehend Pricing
Not only do the different operations like query or scan differ significantly in pricing, but also the capacity modes.
Understanding capacity modes, query versus scan operations, and other details about DynamoDB is crucial for comprehending its pricing, as it directly influences the cost of using the service. Different operations and capacity modes follow distinct pricing models, and grasping these nuances can assist you in optimizing your usage and preventing unforeseen expenses.
A Deep Dive into DynamoDB's Pricing Structure
Understanding DynamoDB's pricing structure is essential for optimizing usage and avoiding unexpected costs, so let's explore it in detail using example values from the us-east-1 region as of June 2023.
Pricing for On-Demand Read/Write Capacity Units
Each API call passing through one of your DynamoDB tables is measured and billed in read request units. You have the option to select the consistency for these read requests, which will impact the granularity of the charges and how the read kilobytes are divided into read request units.
| Request Mode | Required Read Request Units to read 4 KBs |
| strongly consistent | 1 |
| eventually consistent | 0.5 |
| transactional | 2 |
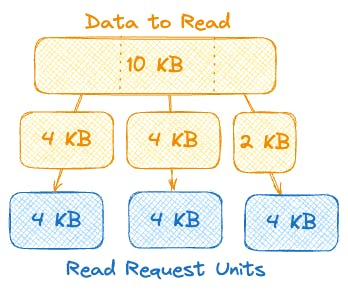
What does this mean? If we're going to read 10 KBs of data in a single query, we'll be charged with a different number of read request units for each of the consistency modes, even though we'll always need three blocks of 4 KBs.
strongly consistent => 3 read request units (1:1)
eventually consistent => 1.5 read request units (0.5:1)
transactional => 6 read request units (2:1)
For writing items, we have to perform a calculation similar to the one for reading items from DynamoDB. The standard write request unit can write up to 1 KB.
| Request Mode | Required Write Request Units to write 1 KB |
| standard | 1 |
| transactional | 2 |
So, writing 10 KB of data requires either 10 write request units or 20 when using transactional mode.
| Table Class | Price |
| Standard | $1.25 per million write request units |
| $0.25 per million read request units | |
| Standard Infrequent-Access | $1.56 per million write request units |
| $0.31 per million read request units |
Charges for Provisioned Read/Write Capacity Units
For provisioned capacity, we need to revise our thinking a little bit. We're still talking about read and write capacity units and they are equally sized in comparison to the on-demand mode: 4 KB and 1 KB.
Also, the factors are equal.
| Request Mode | RCU/WCU Factor | KB |
| [read] strongly consistent | 1 | 4 |
| [read] eventually consistent | 0.5 | 4 |
| [read] transactional | 2 | 4 |
| [write] standard | 1 | 1 |
| [write] transactional | 2 | 1 |
Now we just need to revert our calculation to find out how many RCUs/WCUs we need to cover a certain traffic pattern.
As an example: how many RCUs do we need if we want to write 10 KBs every second?
strongly consistent => 3 RCUs
eventually consistent => 1.5 RCUs
transactional => 6 RCUs
We need three read request units à 4 KBs to cover 10 KBs.
After calculating the required provisioning needs, we can examine the costs associated with those units.
| Table Class | Price |
| Standard | $0.00065 per RCU |
| $0.00013 per WCU | |
| Standard Infrequent-Access | $0.00016 per RCU |
| $0.00081 per WCU |
Pricing for Data Storage and Transfer
You will be charged based on the amount of data stored in your tables. This includes the entire JSON object, which means that field names will also be factored into the calculation. Depending on the enabled features, you're also charged a small additional fee per stored item.
Charges differ based on the table class you use:
| Table Class | Price Per GB and Month | Free Tier |
| Standard | $0.25 | The first 25 GB are free |
| Standard-Infrequent Access | $0.10 | / |
You'll also be charged for outgoing data transfers from DynamoDB to the internet or across AWS regions, while the first 100 GB of data is free each month.
Additional Charges
Although read, writes, and storage are typically the main cost drivers for DynamoDB, the utilization of advanced features can result in additional costs that may also be substantial.
Backup and Restore
With DynamoDB, you can make use of fully managed integrated on-demand backups or point-in-time recovery (PITR). Both are charged differently.
| Backup Mode | Charges per GB and month |
| PITR | $0.20 |
| On-Demand Backup - Warm Storage | $0.10 |
| On-Demand Backup - Cold Storage | $0.03 |
For on-demand backups, you will be charged based on the combined size of all existing backups, whereas for point-in-time recovery (PITR), you will be charged according to the current size of your table.
Global Tables
With DynamoDB, you can effortlessly synchronize your data between multiple regions using global tables. Using replication requests, DynamoDB will automatically transfer data written into one region's table to all other regions included in the global table.

You'll be charged for those replication requests via their used write request units.
| Table Class | Price per Million WRU |
| Standard | $1.875 |
| Standard Infrequent-Access | $2.344 |
Please note that data transferred to other regions will also be included in your data transfer costs.
Data Export to and Import from S3
With DynamoDB, you can also export your data to S3 and also restore the data from S3 to a DynamoDB table.
| Operation | Price per GB |
| Export to S3 | $0.10 |
| Import from S3 | $0.15 |
Similar to other backups, you will be charged per GB of data transferred to S3.
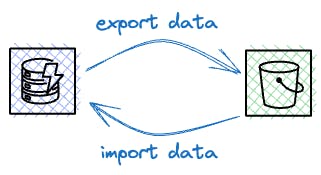
Besides the backup creation expenses, you will also incur charges for data storage in S3 and the PUT requests made by DynamoDB to store your data.
DynamoDB Accelerator (DAX)
DAX is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement. It provides a caching layer between your application and DynamoDB, reducing the need for frequent and expensive read requests to the database.
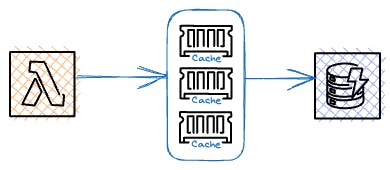
DynamoDB bills DAX capacity hourly, with pricing based on the instance type and the number of nodes in the DAX cluster, charging for partial node hours as full hours.
DynamoDB Streams
DynamoDB Streams is a feature that enables you to capture a time-ordered sequence of item-level modifications in your DynamoDB tables. Whenever an item is created, updated, or deleted in a DynamoDB table, a corresponding event is written to the table's stream. The streaming event is entirely separate from the actual write operation in DynamoDB, allowing you to initiate asynchronous processes.
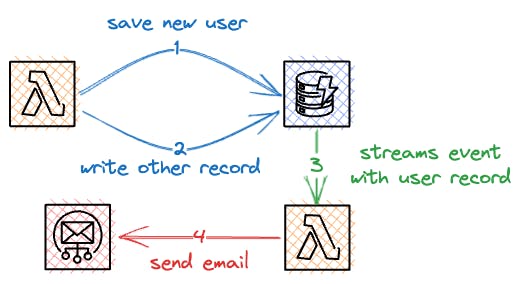
Streams Read Request Units (SRRUs) are the units of read capacity consumed by a GetRecords request on a DynamoDB stream. Each GetRecords request can retrieve up to 1 MB of data or up to 1,000 stream records, whichever comes first.
You will be charged $0.02 per 100,000 DynamoDB read request units, with the first 2.5 million units included in the free tier.
Change Data Capture via Kinesis or Glue
With DynamoDB, you can capture item-level modifications and forward them to an Amazon Kinesis Data Stream or AWS Glue.
The pricing for forwarding these modifications is based on the number of change data capture units, which is calculated based on the number of item modifications captured in 1 KB blocks and is priced at $0.10 per million units.
Best Practices for Minimizing Costs
We have explored the various aspects of DynamoDB's pricing. While it's easy to begin using DynamoDB, it can be challenging to maximize its potential while maintaining low costs. Let's explore some of the best practices.
Choosing the Right Capacity Mode
DynamoDB offers two capacity modes: on-demand and provisioned. On-demand is perfect for infrequent workloads, while provisioned is better for workloads with predictable traffic.
A general rule of thumb:
variable, unpredictable traffic => on-demand
variable, predictable traffic => provisioned
steady, predictable traffic => reserved
DynamoDB reserved capacity mode allows users to commit to a minimum level of consistent read and write capacity for a period of one or three years in exchange for a discounted hourly rate (up to 77%).
Another reminder that the Free Tier for DynamoDB includes 25 RCUs and 25 WCUs for the first 12 months. This means you can read up to 200 KBs (using eventual consistency) and write up to 100 KBs per second without incurring any charges.
This offer is quite generous and difficult to reach with small applications.
Also, let's compare on-demand with provisioned capacity in a small example to see the differences: an application that requires a steady 400 KB of (eventually consistent) reads per second and 50 KBs of writes per second.
Let's do the math for both capacity modes - not counting in the free tier:
| Capacity Mode | Capacity Units Required | Price |
| provisioned | reads: 400 KB / 4 KB = 100 • 0.5 = 50 RCUs | ~$5 |
| writes: 50 KB / 1 KB = 50 • 1.0 = 50 WCUs | ~$24 | |
| on-demand | reads: 2.6m secs • 400 KB / 4 KB • 0.5 = ~134m RRU | ~$34 |
| writes: 2.6m secs • 50 KB / 1 KB • 1.0 = ~4.3m WRU | ~$163 |
As demonstrated in the example, when utilizing provisioned capacity, on-demand is approximately 6.8 times more expensive than provisioned capacity.
This is not realistic, as traffic patterns vary over time and there will always be some overprovisioning. Nonetheless, you can see the advantages of using the provisioned capacity for predictable traffic.
Properly Sizing Read/Write Capacity Units
To avoid overpaying for unused capacity, it's essential to choose the right amount of read/write capacity units. DynamoDB provides tools to help estimate the required capacity based on the expected workload.
We've also covered this in-depth in the provisioned capacity chapter, so be sure to calculate this if your traffic patterns are rather steady and you want to make use of provisioned capacity.
Making Use of Auto-Scaling Rules
If you're using the provisioned capacity mode and your traffic varies over time, make sure to use auto-scaling use to adapt your demands based on your usage patterns.
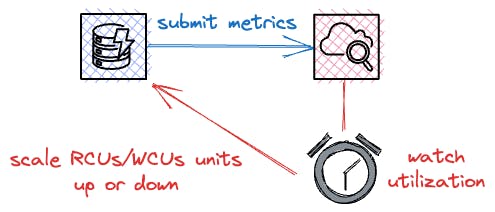
Auto-scaling rules can automatically adjust the provisioned capacity of a table or global secondary index. This is achieved by defining a target utilization percentage and creating CloudWatch alarms that will trigger the auto-scaling action based on metrics such as consumed read or write capacity units, throttled requests, or latency.
This will ensure that the table or index is always provisioned to handle the expected workload while minimizing costs and avoiding performance issues.
Efficient Data Modeling
It is crucial to know the access patterns for a DynamoDB table before starting because it helps you design the table schema.
Understanding the access patterns enables you to select the appropriate partition key, sort key, and indexes for the table, which can significantly affect your application's performance and cost. By being aware of the access patterns, you can also optimize your queries, reduce the number of requests to the database, and avoid the drawbacks of resorting to scans in certain cases, which are highly inefficient and costly.
Moreover: As your provisioned read & write capacity units will be distributed among all internal partitions, it's important to use a well-distributed partition key so items will be spread across all partitions.
If your partition keys are not well-distributed, it will be easier to get your requests throttled as a subset of your partitions (or worse: a single) can receive the read and/or write requests.
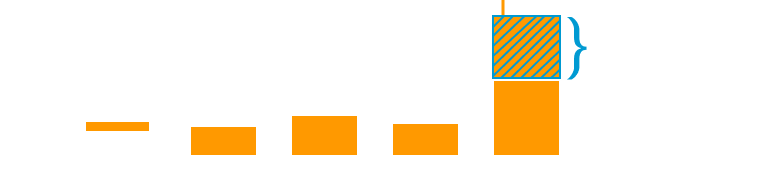
In some way, DynamoDB will increase capacity for hot partitions, as long as the table-level throughput is not exceeded via its adaptive capacity. Even more: If there’s disproportionately high traffic to one or several items in the same partition, DynamoDB will rebalance partitions such that those items don't reside on the same partition.
Caching
Caching data with DynamoDB Accelerator (DAX) can improve performance and reduce costs.
Be aware of some key facts:
DAX is not serverless. It's priced per hour for each node that currently runs.
DynamoDB is very cheap, especially in the beginning. With the free tier and just low demands, you can run several tables for free.
Consider wisely when it's needed to make use of caching.
Using Secondary Indexes
Secondary indexes can also assist in executing queries and minimizing the amount of data scanned. Global secondary indexes can be created even after the table has been established, making it a versatile tool as your application and data model expand.
Conclusion
In conclusion, understanding Amazon DynamoDB's pricing structure is vital for optimizing usage and minimizing costs.
By choosing the right capacity mode, efficiently modeling data, utilizing secondary indexes, and implementing caching when needed, you can ensure that you're getting the most out of this powerful NoSQL database service while keeping expenses under control.
Further Resources
If you're looking to learn more about DynamoDB, we highly recommend The DynamoDB Book by Alex DeBrie. It's an excellent resource for anyone looking to get started with DynamoDB, as well as for those who want to deepen their understanding of the service.
It covers a wide range of topics, from the basics of data modeling, single table design, and querying to advanced topics like streams and transactions. The book is well-written, easy to follow, and includes plenty of examples and practical advice. Whether you're a developer, architect, or DevOps engineer it is an essential resource for mastering the ins and outs of DynamoDB.
We also have a bi-weekly newsletter. Related articles:
Frequently Asked Questions
What is DynamoDB and why is understanding its pricing structure important?
DynamoDB is a NoSQL database service provided by AWS. Understanding its pricing structure is important to optimize usage and minimize costs.What are the two capacity modes offered by DynamoDB, and which one is better for unpredictable traffic?
The two capacity modes are on-demand and provisioned. On-demand is better for unpredictable traffic.What is the Free Tier for DynamoDB, and what does it include?
The Free Tier for DynamoDB includes 25 RCUs and 25 WCUs for the first 12 months. This means you can read up to 200 KBs (using eventual consistency) and write up to 100 KBs per second without incurring any charges.What is the difference between strongly consistent and eventually consistent read requests in DynamoDB?
Strongly consistent read requests return the most up-to-date data but require more read request units. Eventually, consistent read requests return data that may not be up-to-date but require fewer read request units.How can auto-scaling rules help minimize costs in DynamoDB?
Auto-scaling rules can automatically adjust the provisioned capacity of a table or global secondary index based on usage patterns, minimizing costs and avoiding performance issues.