


Securing your DynamoDB Data
Leverage IAM, CloudTrail & S3 to secure your data in DynamoDB


Regardless of what you're building, your customer’s data will most likely be the most valuable asset you’ve got. That’s why your access control rules should be as strict as possible, have good observability in place & prepare for the worst case with different types of backups. Everything to avoid leaking or losing data.
This article will give you on-point descriptions of steps you can take to protect, audit & back up your DynamoDB tables & their data via AWS IAM, CloudTrail, and S3.
AWS IAM Fundamentals
Identity & Access Management is one of AWS's core services, enabling you to manage access control for all resources inside your account. Let’s do a real quick recap on its core principles.
Policies & Types
Policies describe who has access to what. Those permission policies come in two different types: Identity-Based and resource-based.
Identity-Based Policy— attachable permission to a user, group or role in your account.
Resource-Based Policy — attachable permission to a resource. Only possible for certain services like S3. Not possible with DynamoDB.
Resources, Actions, Effects & Principals
A policy can be built out of different elements. The basic ones are:
Principal —defines the user, service, or account which receives the permissions. Only applicable for resource-based policies. For identity-based policies, the role to which the policy will be attached to is the implicit principle.
Resource — the Amazon Resource Names (ARNs) of the resources to which the policy will be applied to.
Action — the action which will be granted. Have a look at AWS’ documentation for a complete list of all actions for all services.
Effect —either
allowordeny. An explicitdenywill always overwrite.
Conditions
There’s the option to attach conditions to policies, so that they only apply in specific cases. We’ll have a look at example use cases for DynamoDB in the next chapter.
Achieving Least Privilege for DynamoDB
Now we’ve got the basics covered so we can define our access control rules as restrictive as possible.
Resources and Operations
DynamoDB brings you different types of resources, for which you’re also able to define access separately.
Table:
arn:aws:dynamodb:region:$ACCOUNT_ID:table/$TABLEIndex:
arn:aws:dynamodb:region:ACC_ID:$TABLE/$TABLE/index/$INDEXStream:
arn:aws:dynamodb:region:ACC_ID:table/$TABLE/stream/$STREAM
Working with Terraform or CloudFormation makes it easy to restrict your policies to exactly the resource you want by referencing it, instead of building ARNs by yourself and/or hard coding values.
Terraform — reference your
[aws_dynamodb_table](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/dynamodb_table)directly or export it viaoutput, so you’re able to use it across your modules.CloudFormation — reference your
AWS::DynamoDB::TableviaGetAtt— your able to access the table’s ARN as well as the one of the stream.
Make sure to only grant actions which are really needed by your service. Have a look on all possible permissions.
Permission Boundaries
Another good step to make sure to not accidentally pass too broad permissions to newly created roles and policies is the use of Permissions Boundaries.
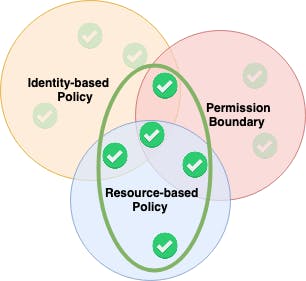
As the diagram shows, permission boundaries are not providing permissions on their own, but only restricting already granted permissions.
In Terraform, you can extend a role with a boundary by providing it via permissions_boundary. If you’re strictly applying new infrastructure via a specific role, a boundary can easily ensure that you’re not mistakenly granting an extensive range of actions or resources.
Conditions for Fine-Grained Policies
In addition to controlling access to DynamoDB API actions, it’s also possible to restrict access to individual data items or even attributes. This is especially an attractive option if you’re on a Single-Table design.
restricting access based on the primary key, e.g. if everything for a user is stored in a single document, you want to make sure it’s not possible to access data of another user.
restricting access to only a subset of attributes, e.g. an application should be able to display the location of its users, but not the personal details like the name or email address.
There’s a good documentation available at AWS with more examples, use-cases and descriptions.
Auditing with CloudTrail
Our first level of security is completed by setting our permissions as strictly as possible. Now we should add some observability.
CloudTrail enables you to continuously monitor & log all actions regarding your infrastructure. All of those actions — like table creations or deletions — can be logged to S3 or CloudWatch.
But that’s not all — there’s also the option to make use of Data Events, which are also available for DynamoDB. With this, you’re able to log DynamoDB object-level API access.
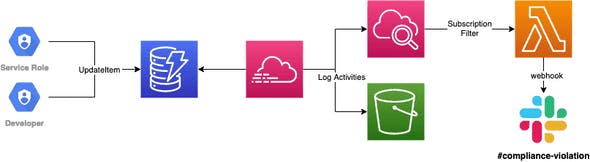
This enables monitoring of roles or identities in your account that are taking changes within your tables. You can find a detailed description on how to set this up with Terraform here, ensuring only expected roles are accessing tables.
Automated Backups
We’ve taken care that our access control rules fit & auditing is in place, so we get notified if there’s suspicious behavior. But human error & malicious behavior is still possible — that’s why it’s always necessary to back up regularly.
Managed: on-demand or continuous
Both of those types are solely managed by AWS.
With on-demand you’re triggering the backup creation yourself (e.g. with scheduled Lambda function) and DynamoDB will create a snapshot of the current state, including all data.
If you’re preferring a continuous option, you can activate Point-in-Time recovery (PITR). This will enable DynamoDB to create continuous incremental backups, which allows you to restore your table to any point in the last 35 days (comes with a higher pricing).
S3 exports
Both managed options do not protect you from (accidental) table deletions. That’s why regular exports to S3 are recommendable. It’s also a feature by AWS (requires enabling PITR).
const { DynamoDB } = require('aws-sdk')
const ddb = new DynamoDB({ region: 'eu-central-1' })
ddb.exportTableToPointInTime({
TableArn: '$TABLE_ARN',
S3Bucket: '$BUCKET_NAME',
ExportTime: 1596232100,
S3Prefix: 'backups',
ExportFormat: 'DYNAMODB_JSON'
})
The main purpose for the exported backup to S3 is, that you can enable Object Locks, either with…
Governance mode — objects only be altered/deleted with specific permissions or
Compliance mode — objects can’t be altered/deleted at all, not even by the root user
Even if your account gets nuked, we won’t lose our backups because bucket deletion is impossible due to our locked objects.
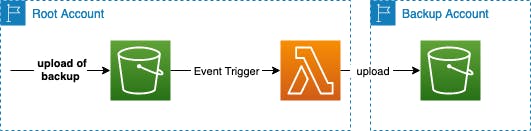
S3 Replication to another account
We’ve covered table drops & complete account takeovers.
But what’s happening if your account gets deleted? Not even compliance mode will protect in this case and the backups are gone for good.
That’s why you should replicate backups to another dedicated backup account. This is easily possible by granting inter-account permissions and automatically replicating all files from your main bucket to the replication one with S3 notifications triggering a Lambda function.
Conclusion
We’ve gone through AWS’ IAM principles and how to use them accordingly to restrict our permissions as much as possible. Additionally, we’ve had a look into CloudTrail to give us auditing and observability. Last, we’ve covered how to automatically create backups, either in DynamoDB or to S3 — including replications to other accounts as a second layer.