


Masking Sensitive Data with Amazon CloudWatch Logs Data Protection Policies


Infographic

Data generation is undeniably the lifeblood of businesses worldwide. Whether it's customer information, operational metrics, or sensitive financial records, the value of data cannot be overstated. Organizations increasingly rely on cloud-based services for their data management and monitoring needs.
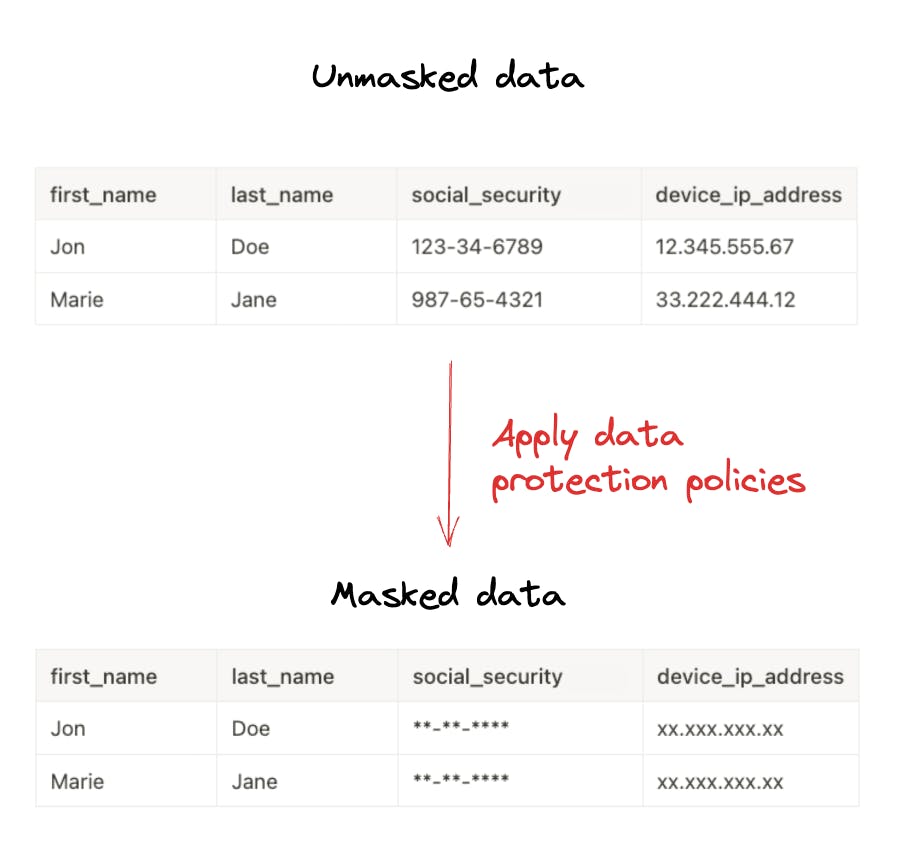
Data masking is a key strategy in data protection, ensuring the confidentiality and security of valuable data. By masking sensitive information, organizations can prevent unauthorized access and mitigate the risks of data breaches or misuse.
Data masking involves replacing sensitive data with fictitious or scrambled values while preserving the format and structure of the original data. This technique allows organizations to use data for various purposes, such as development, testing, or analytics, without exposing sensitive information to individuals who don't require access.
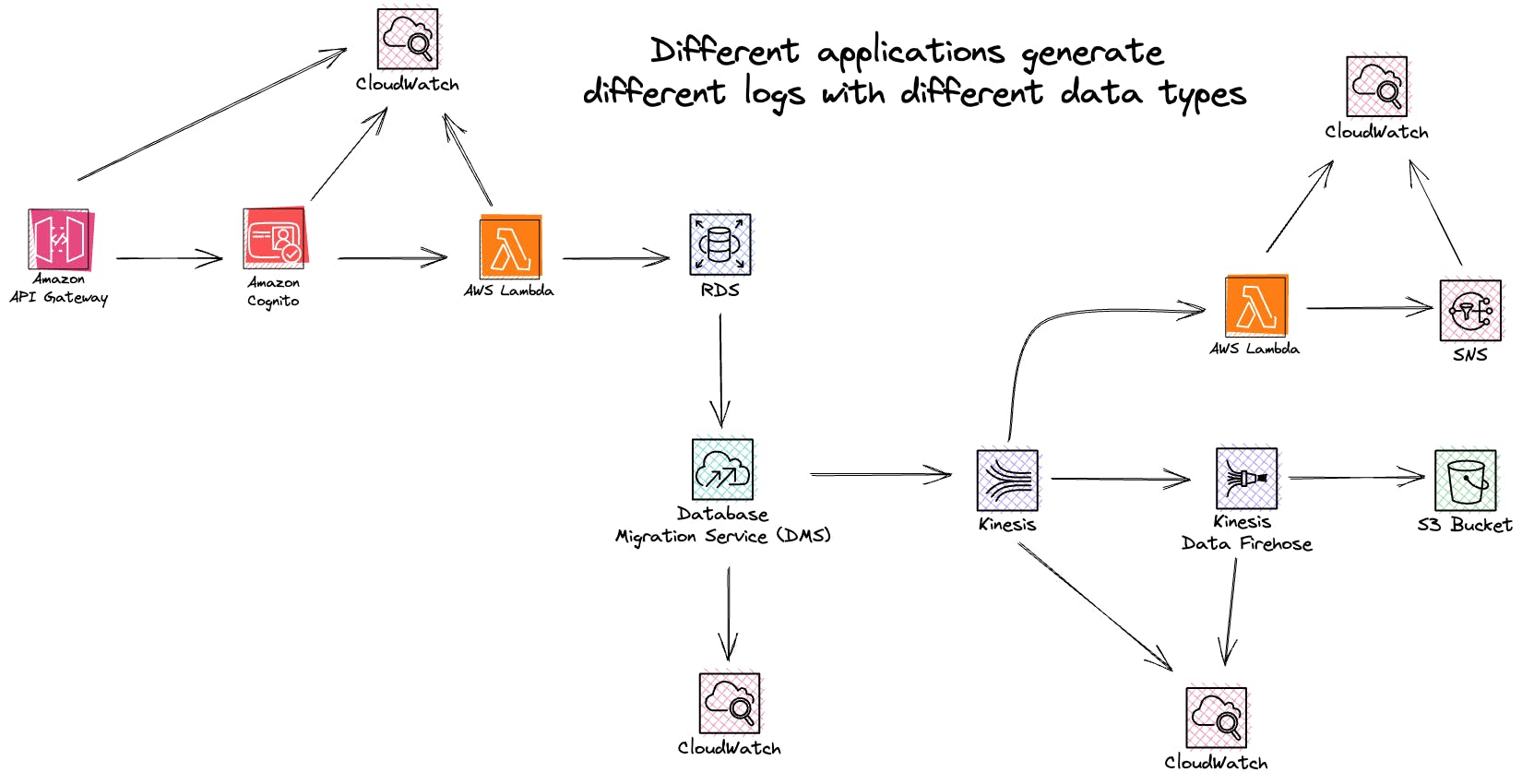
Organizations deal with many applications, data streams, queues, and workflows in the technology landscape that often operate asynchronously and synchronously. Each of these components presents its challenges regarding safeguarding sensitive information.
Different types of data, including credentials, financial records, device identifiers, medical information, and protected health information (PHI), require masking to uphold privacy regulations and maintain data integrity. Furthermore, certain types of data may also fall under personally identifiable information (PII) categories, further necessitating robust masking practices.
By implementing data masking, organizations can balance data accessibility and security. It supports compliance with industry regulations, strengthens data privacy initiatives, and mitigates the potential risks of unauthorized data exposure.
Amazon CloudWatch Logs offers tools for monitoring, managing, and protecting the data that flows through CloudWatch. This article will explore the features CloudWatch employs to maintain the integrity and confidentiality of your information. Whether you're a seasoned AWS user or new to the platform, understanding data protection within CloudWatch is vital to maintaining a secure and compliant cloud environment.
Sensitive Data in CloudWatch Log Groups
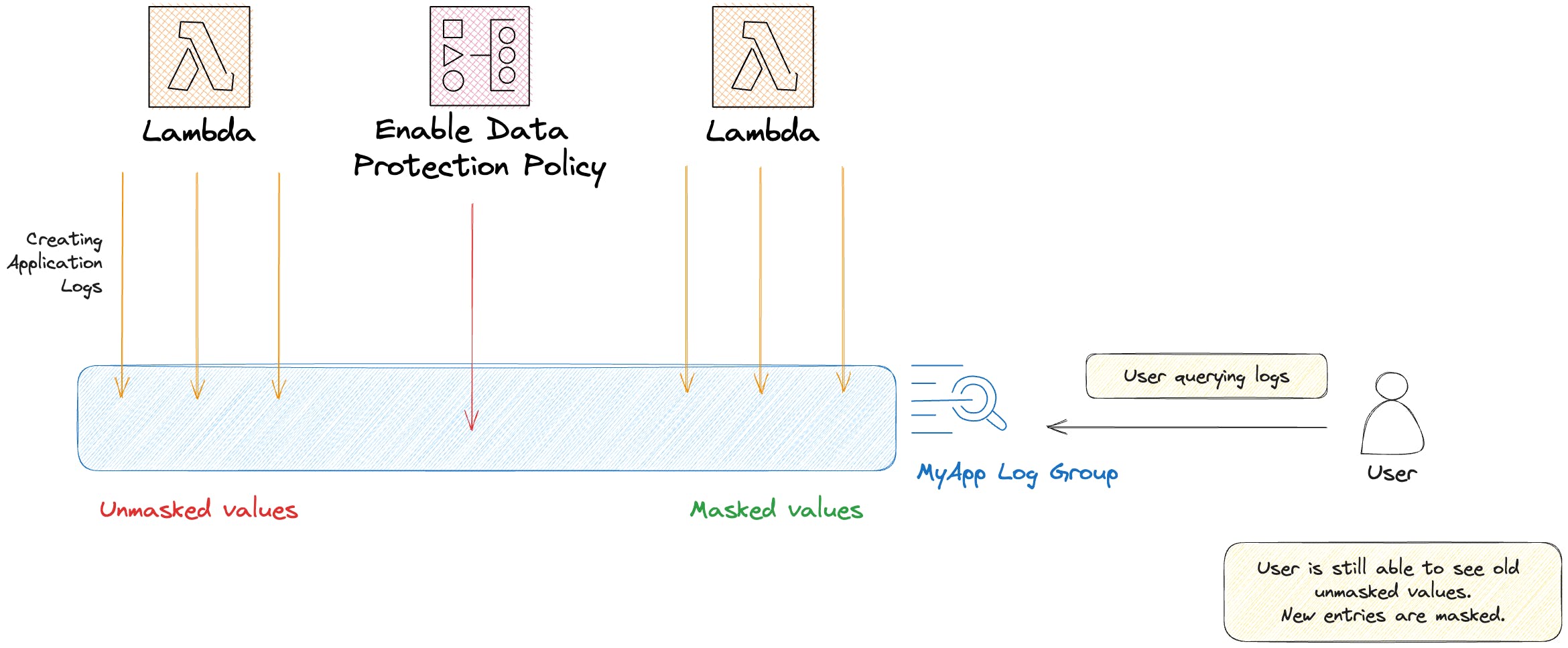
You can enhance the protection of sensitive data ingested into CloudWatch Logs by utilizing log group data protection policies. These policies allow you to audit and conceal sensitive information in log events that the log groups within your AWS account ingest.
CloudWatch Logs uses data protection policies to select the sensitive data you want to scan and the actions you want to take to protect that data. To select the sensitive data of interest, you use data identifiers.
When establishing a data protection policy, sensitive data that matches the designated data identifiers is automatically masked by default. Unmasking this data is only possible for users who possess the logs:Unmask IAM permission.
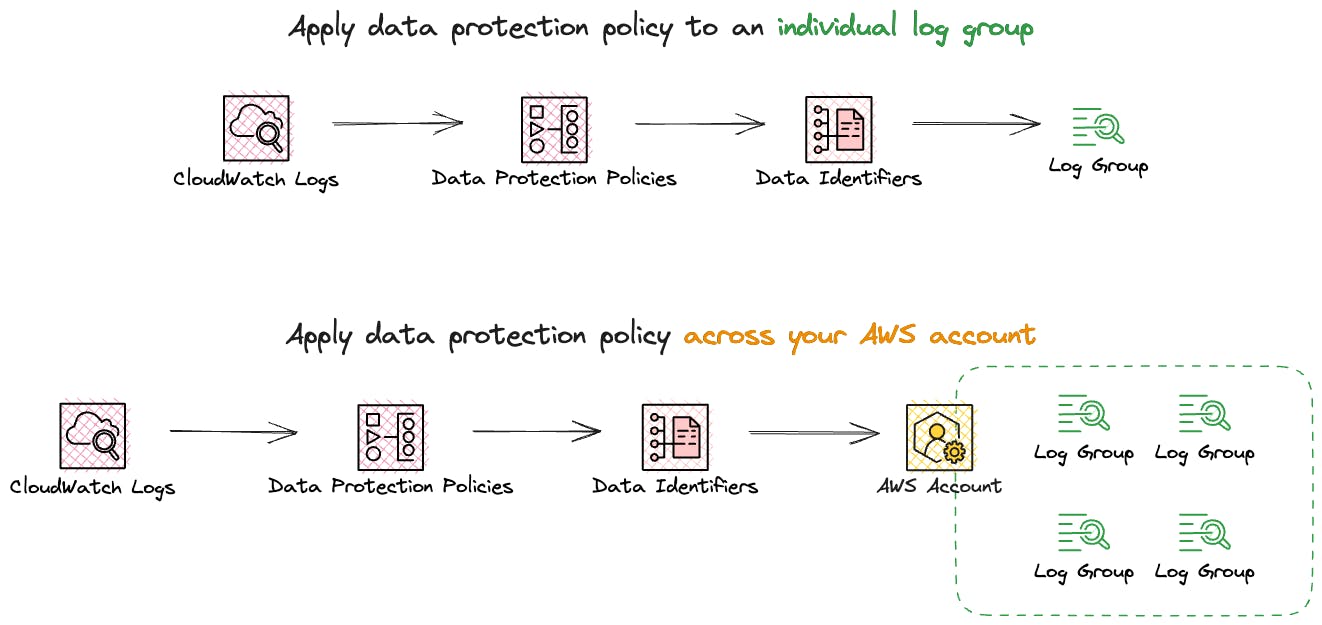
Data protection policies can be implemented at two levels: for all log groups across your entire account or specific individual log groups. When a policy is created at the account level, it applies to existing and any log groups created in the future.
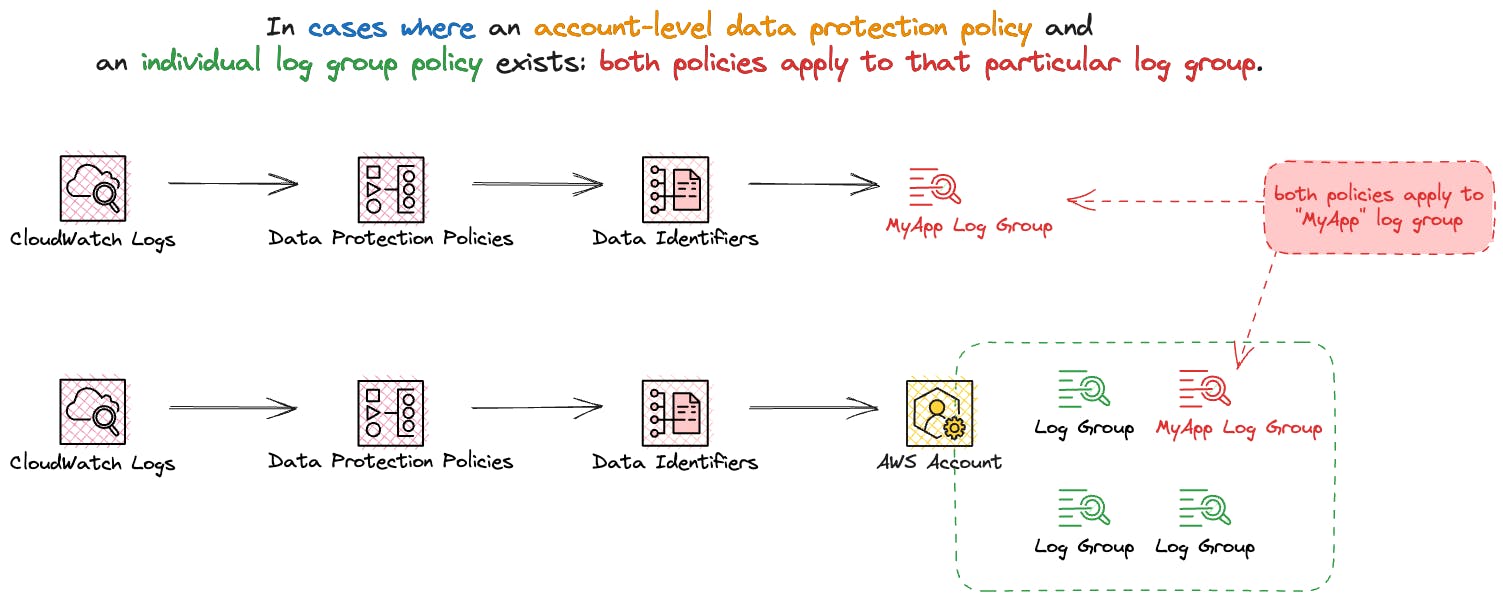
In cases where both an account-level data protection policy and an individual log group policy exist, both policies apply to that particular log group. All data identifiers specified in either policy are subject to auditing and masking within that log group.
Understanding Data Protection Policies
Data Protection Policies are JSON documents defining elements and statements.
Only one data protection policy can be defined per log group. In cases where both an account-level data protection policy and an individual log group policy exist, both policies apply to that particular log group.
Data Protection Policies use pattern-matching and machine-learning models to detect sensitive data. You define which data type you want to detect by importing one of the data identifiers managed by the CloudWatch service.
To act upon data identifiers found, you can define audit and de-identify operations. These operations let you log the sensitive data that is found (or not found) and mask the sensitive data when the log events are viewed. You can have one or more deny or de-identify statements, but only one audit statement.
Sensitive data is only masked when it enters the log group. Any data ingested before setting up the policy remains unmasked.
To define a data protection policy for a specific log group, we can use the AWS CLI:
aws logs put-data-protection-policy \
--log-group-identifier "log-group-my-app" \
--policy-document file://policy.json \
--region ap-southeast-2
{
"Name": "data-protection-policy",
"Description": "test description",
"Version": "2021-06-01",
"Statement": [{
"Sid": "audit-policy",
"DataIdentifier": [
"arn:aws:dataprotection::aws:data-identifier/EmailAddress",
"arn:aws:dataprotection::aws:data-identifier/DriversLicense-US"
],
"Operation": {
"Audit": {
"FindingsDestination": {
"S3": {
"Bucket": "EXISTING_BUCKET"
}
}
}
}
},
{
"Sid": "redact-policy",
"DataIdentifier": [
"arn:aws:dataprotection::aws:data-identifier/EmailAddress",
"arn:aws:dataprotection::aws:data-identifier/DriversLicense-US"
],
"Operation": {
"Deidentify": {
"MaskConfig": {}
}
}
}
]
}
The JSON above performs the following:
The first statement must include both a
DataIdentifierarray and anOperationproperty with anAuditaction. This is required to find sensitive data terms.The
Auditaction must contain anFindingsDestinationobject. You can optionally use theFindingsDestinationobject to list one or more destinations to send audit findings reports to (it can be empty, like{}). If you specify destinations such as log groups, Amazon Kinesis Data Firehose streams, and S3 buckets, they must already exist in your account.The second statement must include both a
DataIdentiferarray and anOperationproperty with anDeidentifyactionThe
DataIdentiferarray must exactly match theDataIdentiferarray in the first statement of the policy.The
Operationproperty with theDeidentifyaction is what masks the data, and it must contain the"MaskConfig": {}object. The"MaskConfig": {}object must be empty.We are using two types of
DataIdentifierin this JSON. One is language and region-independent (EmailAddress) and one is region-dependent using the ISO 3166-1 alpha-2 identifier (DriversLicense-US). We'll explore them in the next section.
The syntax to apply the data protection policy to the account level is:
aws logs put-account-policy \
--policy-name MyAccountPolicy --policy-type "DATA_PROTECTION_POLICY" \
--policy-document file://policy.json \
--scope "ALL" \
--region ap-southeast-2

It's important to note that each log group can be associated with only one log group-level data protection policy. However, this policy can encompass multiple managed data identifiers for auditing and masking purposes, with a character limit of 30,720 characters.
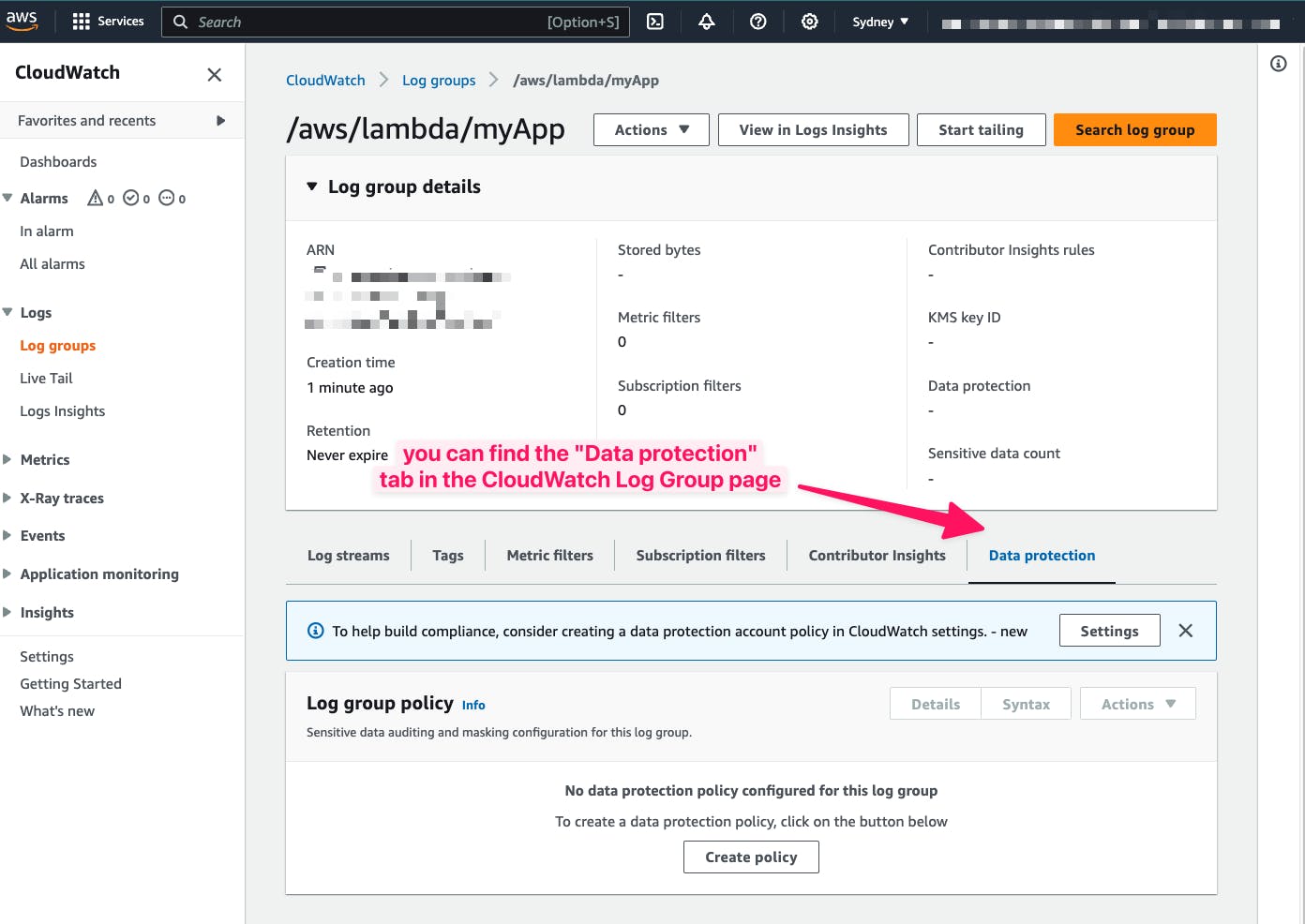
You can find the "Data protection" tab on the CloudWatch Log Group page in the AWS console:
Understanding Data Identifiers
Data identifiers are managed by the CloudWatch service. They use pattern-matching and machine-learning models to detect sensitive data. You define which data type you want to detect by importing one of the data identifiers ARNs.
We have two types of data identifiers:
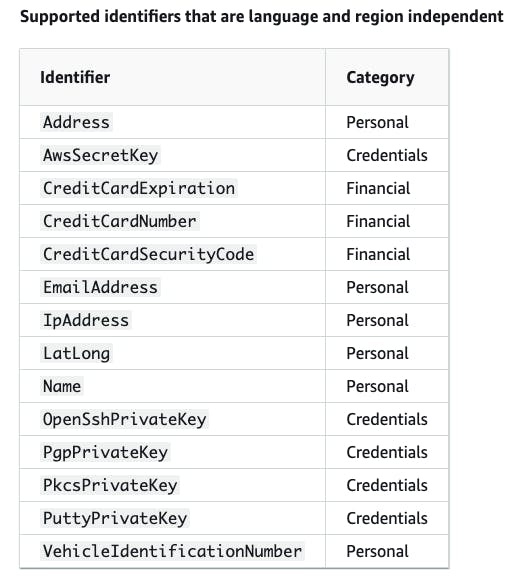
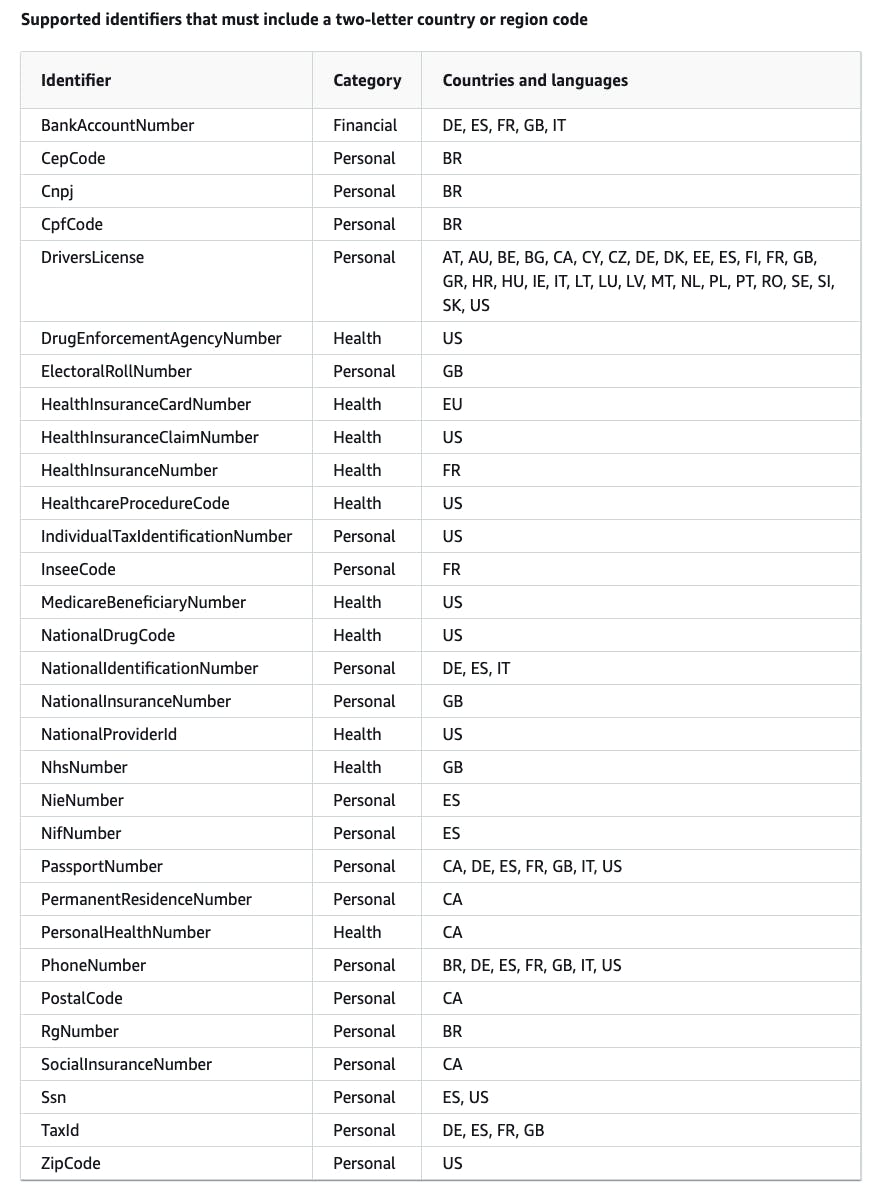
Language and region-independent
Region-dependent
The "region" term above is not the AWS region. Instead, it is the abbreviation of countries and regions defined by ISO 3166.
For some types of sensitive data, the data identifier model scans for keyword variations in the data and finds a match only if it finds that keyword. If a keyword contains a space, the model automatically matches keyword variations that are missing the space or contain an underscore (_) or hyphen (-) instead of the space. In some cases, CloudWatch Logs also expands or abbreviates a keyword to address common variations of the keyword.
One example is the Credentials data identifier. It can scan for AWS credentials and private keys and the AWS credentials require a range of keywords for pattern-matching:
| Type of data | Data identifier ID | Keyword required | Countries and regions |
| AWS secret access key | AwsSecretKey | aws_secret_access_key, credentials, secret access key, secret key, set-awscredential | All |
| OpenSSH private key | OpenSSHPrivateKey | None | All |
| PGP private key | PgpPrivateKey | None | All |
| Pkcs Private Key | PkcsPrivateKey | None | All |
| PuTTY private key | PuttyPrivateKey | None | All |
| Credential data identifier ARNs |
arn:aws:dataprotection::aws:data-identifier/AwsSecretKey |
arn:aws:dataprotection::aws:data-identifier/OpenSshPrivateKey |
arn:aws:dataprotection::aws:data-identifier/PgpPrivateKey |
arn:aws:dataprotection::aws:data-identifier/PkcsPrivateKey |
arn:aws:dataprotection::aws:data-identifier/PuttyPrivateKey |
Each managed data identifier is designed to detect a specific type of sensitive data, such as credit card numbers, AWS secret access keys, or passport numbers for a particular country or region. When you create a data protection policy, you can configure it to use these identifiers to analyze logs ingested by the log group and take action when they are detected.
Here are some categories of sensitive data that managed data identifiers can cover:
Credentials, such as private keys or AWS secret access keys
Financial information, such as credit card numbers
Personally Identifiable Information (PII) such as driver’s licenses or social security numbers
Protected Health Information (PHI) such as health insurance or medical identification numbers
Device identifiers, such as IP addresses or MAC addresses
The data identifiers list will vary based on the category and region/country to which you apply it. The complete list of data you can protect can be found in the CloudWatch Data Identifiers documentation.
In the AWS console, after clicking on the "Create policy" button, you are presented with the list of data identifiers and if you want to send the audit findings to a destination:
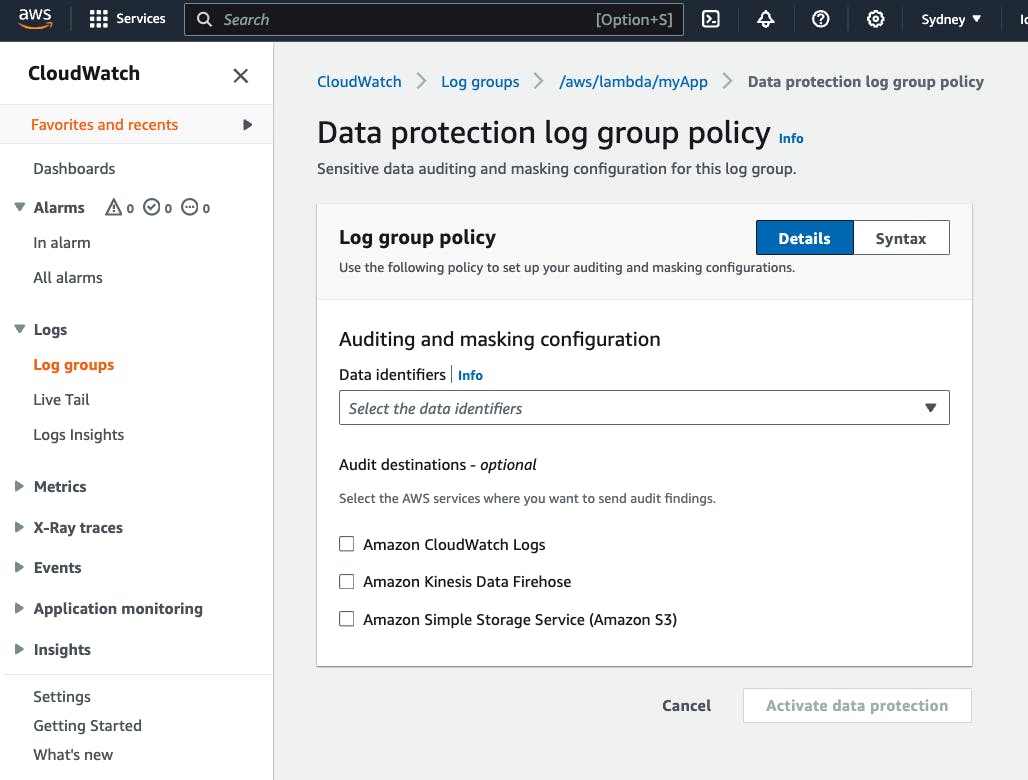
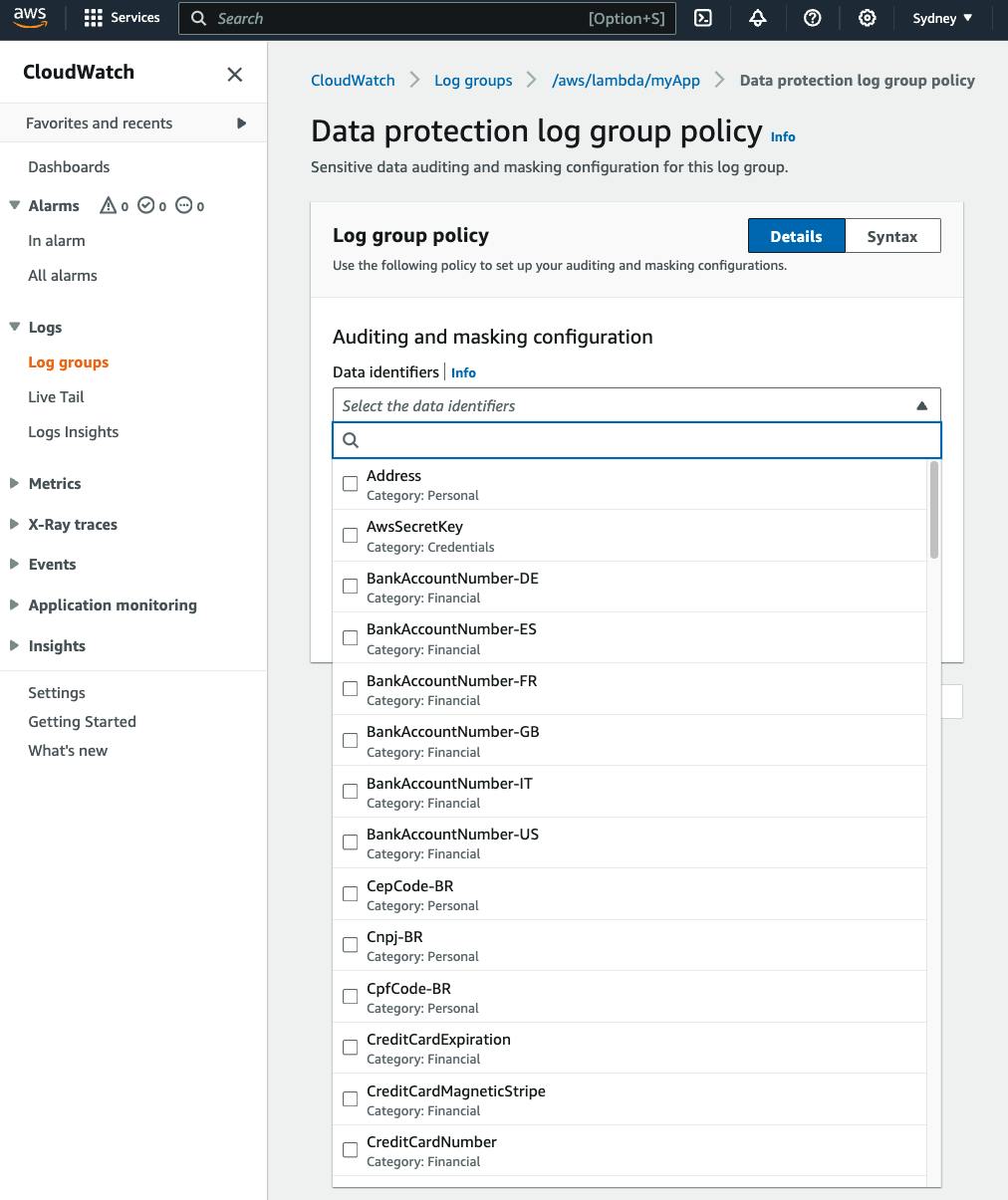
Let's select AwsSecretKey and activate our data protection policy:
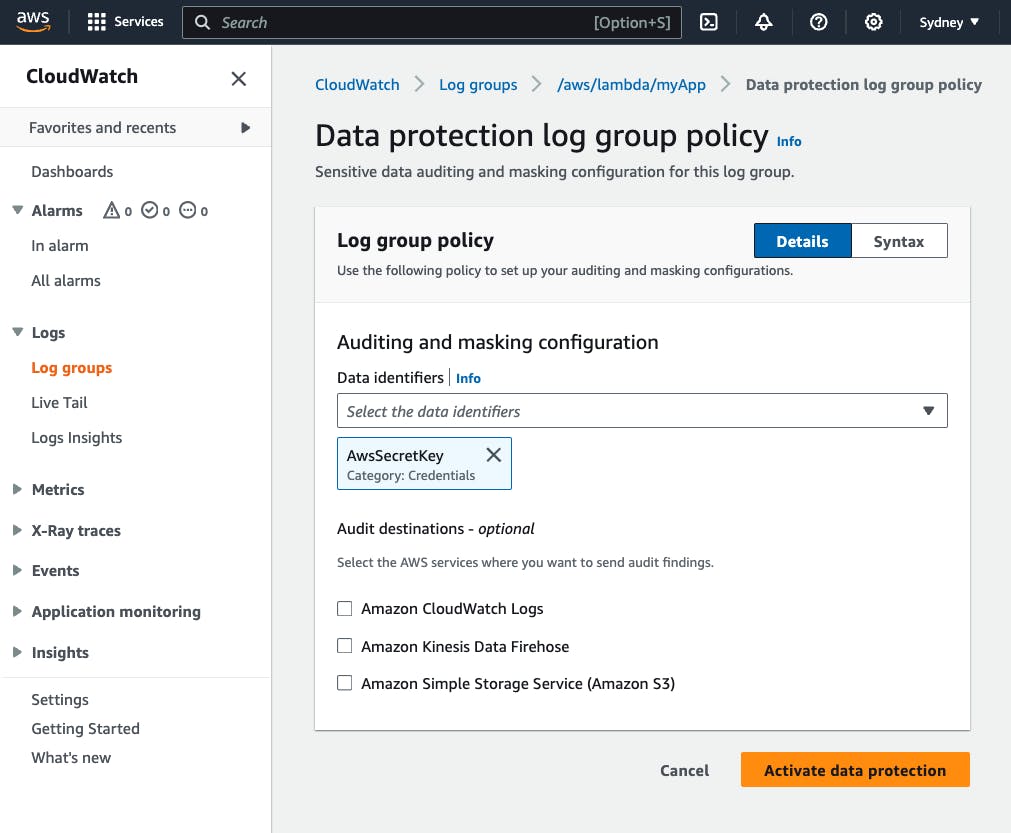
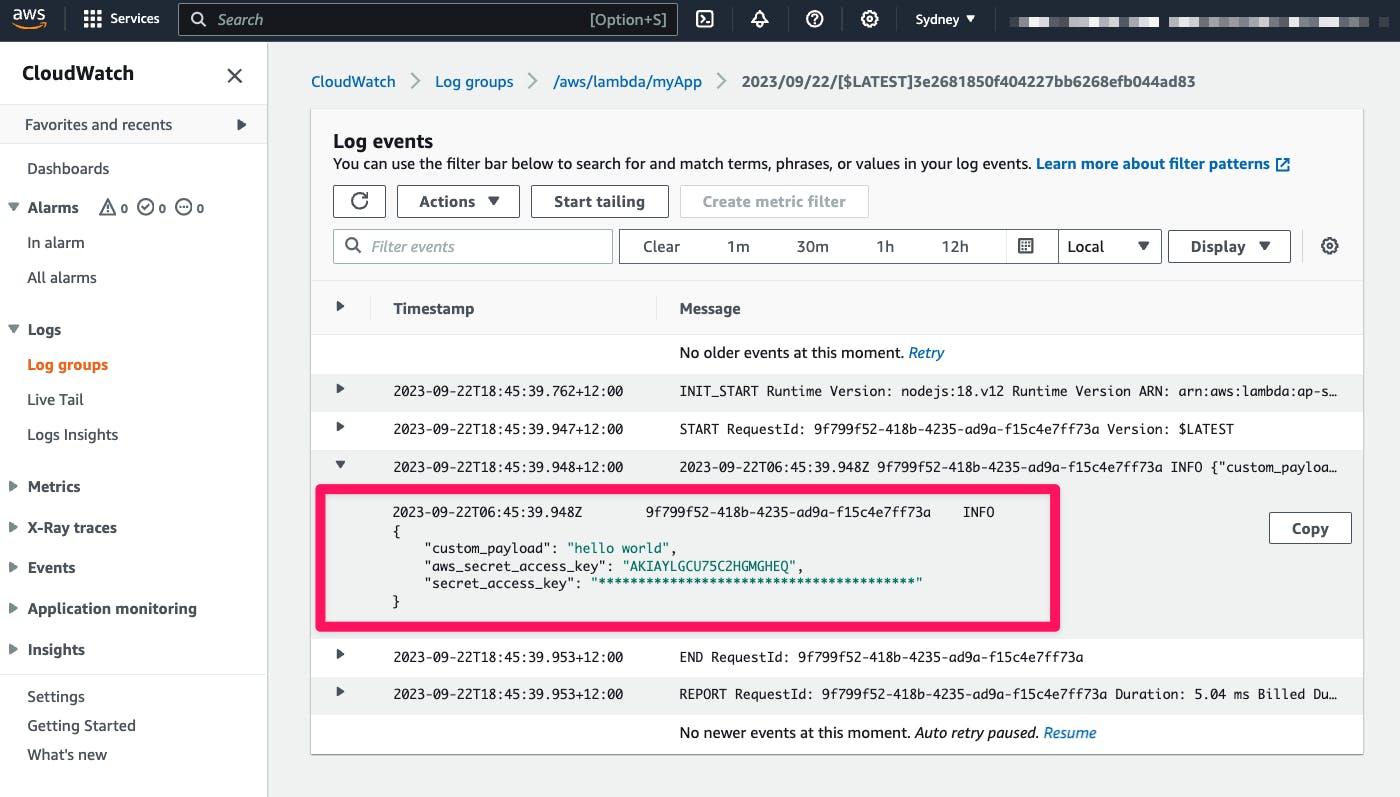
Next, let's create an AWS Lambda that logs IAM User credentials:
export const handler = async (event) => {
const payload = {
custom_payload:"hello world",
aws_secret_access_key: "AKIAYLGCU75C2HGMGHEQ",
secret_access_key: "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",
}
console.log(payload)
};
As a result, the log is masked in CloudWatch Logs:
Understanding Audit Reports
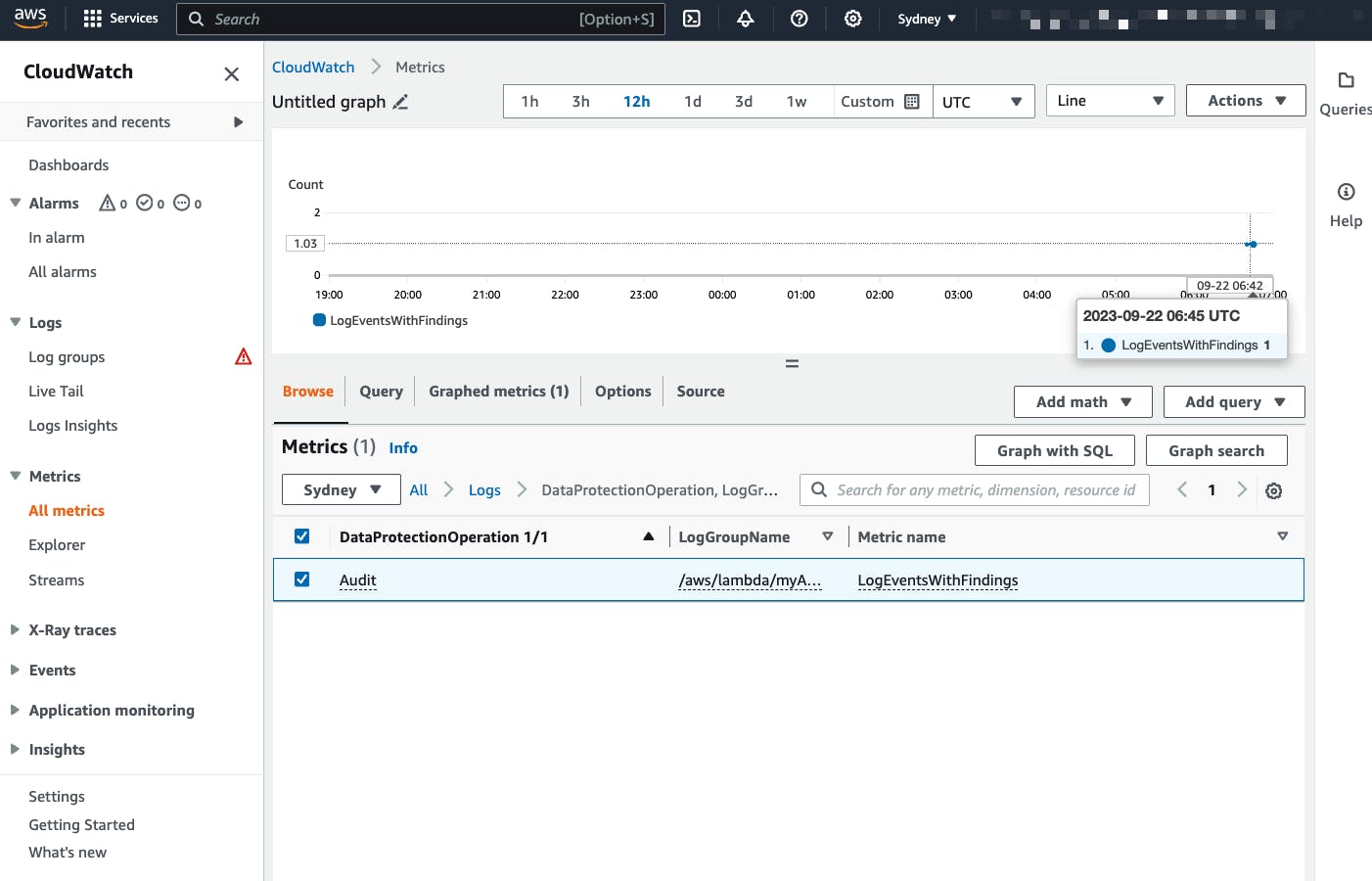
A metric is emitted to CloudWatch when sensitive data is detected that matches the data identifiers you select. This is the LogEventsWithFindings metric emitted in the AWS/Logs namespace.
You can use this metric to create CloudWatch alarms and visualize them in graphs and dashboards. Metrics emitted by data protection are free of charge.
If you set up CloudWatch Logs data protection audit policies to write reports to CloudWatch Logs, Amazon S3, or Kinesis Data Firehose, these findings reports are JSON-based. CloudWatch Logs writes one findings report for each log event that contains sensitive data:
{
"auditTimestamp": "2023-01-23T21:11:20Z",
"resourceArn": "arn:aws:logs:us-west-2:111122223333:log-group:/aws/lambda/MyLogGroup:*",
"dataIdentifiers": [
{
"name": "EmailAddress",
"count": 2,
"detections": [
{
"start": 13,
"end": 26
},
{
"start": 30,
"end": 43
}
]
}
]
}
The report includes the following fields:
The
resourceArnfield displays the log group where the sensitive data was found.The
dataIdentifiersobject displays information about the findings for one type of sensitive data you are auditing.The
namefield identifies which type of sensitive data this section is reporting about.The
countfield displays the number of times this type of sensitive data appears in the log event.The
startandendfields show where each occurrence of the sensitive data appears in the log event by character count.
The first email address starts at the 13th character of the log event and ends at the 26th character.
The second email address runs from the 30th character to the 43rd character.
Even though this log event has two email addresses, the value of the LogEventsWithFindings metric is incremented only by one because that metric counts the number of log events that contain sensitive data, not the number of occurrences of sensitive data.
Conclusion
Amazon CloudWatch Data Protection Policies safeguard sensitive data within your AWS environment. Using data protection policies and managed data identifiers, you can efficiently audit and mask sensitive information in log events.
This proactive approach to data security ensures confidentiality and compliance while findings reports and metrics help you stay vigilant against potential threats.
CloudWatch Data Protection Policies improve your environment's security and ensure compliance within the cloud ecosystem.
If you'd like to learn more about CloudWatch, check out the related articles on our blog.