


Building a Serverless Chat App with Contextual Note Integration Featuring Amazon Bedrock, the OpenAI API, and SST


In this article, we'll explore how to build a serverless chat application that uses Amazon Bedrock and the OpenAI API. We'll use SST (Serverless Stack) to develop and deploy the application on AWS, featuring Next.JS for the frontend and DynamoDB and Lambda for backend services.
Here is the accompanying repository:
Introduction
The primary focus is on leveraging Amazon Bedrock and the OpenAI API for chat functionalities with contextual support.
By utilizing a serverless architecture, we'll create a scalable, maintainable, and cost-efficient (close-to-zero buckets and 100% pay-per-use priced!) application.
Overview of the Project
The project involves creating a chat application that not only allows real-time communication but also uses contextual notes to enrich conversations.
This means that you can create and store notes that will be passed as a context to your chat. The model can reference and utilize previously stored information to make conversations more useful.
The integration of Amazon Bedrock provides access to several different AI models (e.g. Titan from Amazon or Claude from Anthropic) that can analyze and understand the context. Additionally, we'll also integrate with the OpenAI API.
Technologies used
The technologies we're using are 100% serverless and pay-per-use. Everything will be deployed to AWS and won't result in any hourly costs:
Amazon Bedrock & OpenAI API: Used for processing and understanding natural language within the chat.
Serverless Stack (SST): A framework that (drastically) simplifies building and deploying serverless applications on AWS.
Next.JS: A React framework that enables server-side rendering and static website generation to build the frontend.
DynamoDB: A fast and flexible NoSQL database service for all document-based applications.
Lambda: A compute service that lets you run code without provisioning or managing servers.
Architecture of the Application
The architecture of the application is very simple and straightforward:
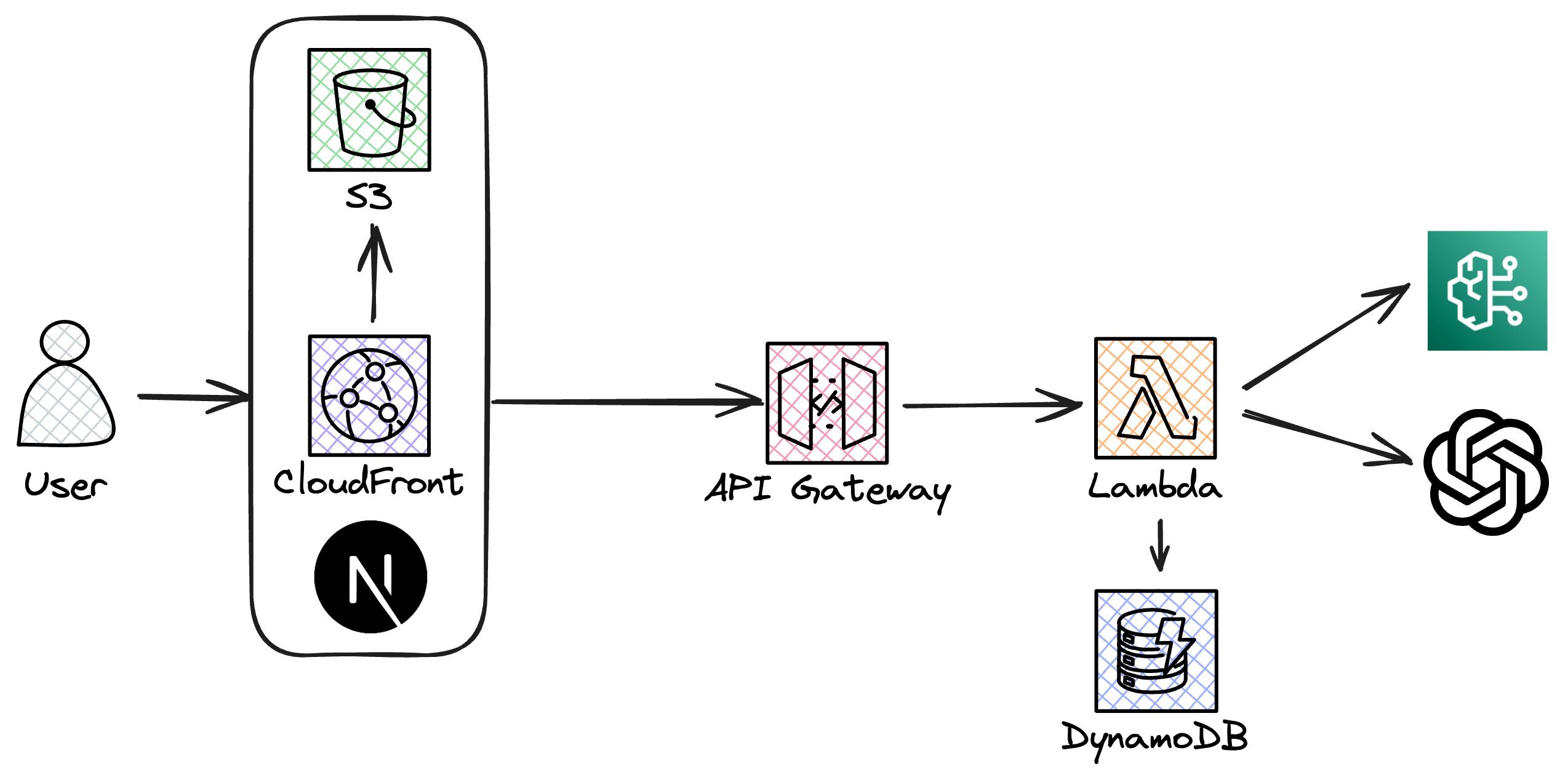
Frontend: A simple web app built with Next.JS. It interacts with the backend through API Gateway, fetching data from and sending data to the AWS Lambda functions.
Backend: Several AWS Lambda functions handle our business logic, including simple authentication (via an API key), message processing, and interactions with the database and our external APIs from Amazon Bedrock and OpenAI.
Data Storage: Uses DynamoDB to store chat messages and notes.
All infrastructure is managed by SST, meaning we can write highly abstracted Infrastructure-as-Code and SST does the heavy lifting.
Getting Started
Necessary Prerequisites and Installations
Before diving into the development of our app, there are a few prerequisites that need to be addressed:
node/pnpm: As this is a TypeScript/Node.js project, we need to have Node.js installed. As we're a fan ofpnpm, we'll use it instead ofnpm.AWS Account: You will need an active AWS account to deploy our application that uses various services such as AWS Lambda, DynamoDB, and API Gateway. If you don't already have an account, you can easily sign up at AWS. Disclaimer: A credit card is required.
AWS CLI: Make sure to install the AWS CLI (following the instructions on the official AWS CLI page or use a package manager like homebrew) and configure it with your credentials. For this you'll need an IAM (or Identity Center) user with the
AdministratorAccesspolicy attached (or more minimal, fine-grained permissions that still cover the services and actions we use). 💡 Please do not use your root user. Afterward, please configure the AWS CLI with your credentials and default region (us-east-1) by usingaws configure.OpenAI API Access: Access to the OpenAI API is required. You must apply for access at OpenAI, and once approved, obtain an API key that will allow you to make requests to the OpenAI API.
Amazon Bedrock Access: Since this application uses Amazon Bedrock, we also need to request access to different models from Amazon, Anthropic, or Mistral. This can be done on the Model Access page from Bedrock.
Introduction to SST
Serverless Stack (SST) is an open-source framework designed to make it easier to build serverless applications with AWS.
SST extends AWS CloudFormation (currently on the way of replacing CloudFormation with Pulumi via SST Ion) and provides a higher level of abstraction to simplify the deployment and management of serverless resources.
It also includes a local development environment that allows you to test your serverless applications locally, using live AWS cloud resources.
One of the key features of SST is the Live Lambda Development. It enables you to work with your Lambda functions locally while directly interacting with deployed resources in AWS. This is done by proxying your calls to your real Lambda functions to your local code! 🪄
Another significant feature of SST is the SST Console, a powerful web-based dashboard that provides real-time insight into your app. It enhances the development experience by offering a unified view of your resources and logs. It also allows you to quickly debug issues directly from the console by invoking functions and seeing log outputs. In combination with the live development mode for Lambda, this is a game changer for developers. This is definitely the case for us at least!
Setting Up Our Project
With the necessary tools installed and the first knowledge about SST, it's time to dive into setting up our project.
This stage is critical as it lays the foundation for the entire application, from backend to frontend.
We'll start by creating a new SST project, defining APIs using AWS Lambda for our compute, and setting up a new frontend application using NextJS.
💡 You can check out our repository, or follow along, but we won't cover every detail in this guide.
Creating a new SST Project
To kick off, create a new SST project by running the following command in your terminal. This will generate a new directory with all the necessary files and folders to get started:
pnpm create sst bedrock-openai-experimental-chat
cd bedrock-openai-experimental-chat
This command sets up a new SST project with a default template, which includes basic configuration for deploying to AWS. The generated project will include several example files like a sample API and some shared core files.
By running npx sst dev (you can install npx globally via npm i -g npx to execute any npm package on-demand) we'll deploy a new stack to AWS which will use our local Lambda code. Every update we make in the code will be automatically and immediately updated on AWS.
Defining APIs with Lambda as Compute
Once your SST project is set up, the next step is to define our APIs. SST makes it very easy to create and deploy AWS Lambda functions.
But how does everything play together at SST? Let's go one step back.
It all starts in the sst.config.ts file:
import { SSTConfig } from 'sst';
import { Stack } from './stacks/index';
export default {
config(_input) {
return {
name: 'bedrock-openai-experiments-chat',
region: 'us-east-1',
};
},
stacks(app) {
app.stack(Stack);
},
} satisfies SSTConfig;
Here we can see the region we're deploying to (us-east-1). You can change this, but be aware that Bedrock for example is not available in all regions yet. Furthermore, we can see that we're bootstrapping our stack from ./stacks/index.
With an index file, we can create a fine-grained file structure of our stack that is easy to understand. In our case, we'll split into
a
backend.ts, containing our API definitions and DynamoDB tables.a
frontend.ts, containing our NextJS app that will be deployed to CloudFront, S3, and Lambda.
Let's have a look how our function that creates our APIs look like:
function createApi(stack: Stack, tables: Table[], apiKey: string): Api {
// Our OpenAI API Key
// this needs to be provided to SST once per stage via the following command:
// 'npx sst secrets set OPENAI_API_KEY sk-Y....BcZ'
const openAiApiKey = new Config.Secret(stack, 'OPENAI_API_KEY');
const api = new Api(stack, 'api', {
defaults: {
function: {
bind: [...tables, openAiApiKey],
environment: {
API_KEY: apiKey,
},
timeout: 600,
memorySize: 2048,
diskSize: 512,
permissions: [
new PolicyStatement({
actions: [
'bedrock:ListFoundationModels',
'bedrock:InvokeModel'
],
effect: Effect.ALLOW,
resources: [`*`],
}),
],
},
},
cors: true,
routes: {
'GET /api/v1/notes': 'packages/functions/src/notes-api.list',
// [...] more routes
},
});
return api;
}
SST abstracts a lot away from us, as it will not only create our Lambda function but will also take care of creating an HTTP API Gateway and enabling CORS.
What we can see in the definition is, that we'll also
allow our functions to talk to the Bedrock service via additional
permissions.allow our functions to write to our DynamoDB tables that we have created beforehand. Providing constructs via
bindto another construct will automatically provision the necessary permissions.passing the
OPENAI_API_KEYsecret to our function. SST will take care of storing the secret securely in the parameter store (SSM) of the Systems Manager service. The value will be fetched from SSM by the Lambda function when the cold start happens. We don't need to take care of anything else here!
What we can also see: the referenced Lambda functions can be found at packages/functions/src. They do not contain all the code, but also shared/common code that can be used across all of our functions from packages/core.
This includes for example the logic to read from and write to DynamoDB tables.
A New Frontend Application with Next.JS
Our backend part is ready to go. But we don't have any frontend for it yet!
Let's change that by creating a new Next.JS application inside our packages folder via pnpm create next-app. As the application name, we'll simply choose app.
Once you have completed the wizard, we need to connect our frontend to SST so that we're able to get into the benefits of the live development mode. This is done by adapting the dev script to the following command: sst bind next dev.
If SST was started in another terminal tab via npx sst dev, starting our frontend via npm run dev will enable us to work with our local function code, even if we invoke the real HTTP API Gateway URLs.
Additionally, all the environment variables we've passed to our frontend, like the API Gateway URL and the API key, will be available immediately.
Let's have a look at our NextjsSite definition:
function createApp(stack: Stack, apiUrl: string, apiKey: string) {
return new NextjsSite(stack, 'app', {
path: 'packages/app',
bind: [],
environment: {
NEXT_PUBLIC_API_URL: apiUrl,
NEXT_PUBLIC_API_KEY: apiKey,
},
cdk: {
distribution: {
defaultBehavior: {
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
allowedMethods: AllowedMethods.ALLOW_ALL,
},
},
},
});
}
This is all we have to do to get a Next.JS site with supported server-side rendering via CloudFront, S3 and Lambda@Edge functions.
Integrating with Amazon Bedrock
Integrating Amazon Bedrock into our serverless chat application opens up sophisticated capabilities for handling natural language processing.
Let's see how we get access to Amazon Bedrock’s supported models, set up the necessary permissions for our AWS Lambda functions, and to use these models by submitting prompts.
Getting Access to Bedrock's Supported Models
As mentioned earlier, you must request access to Bedrock's supported models via its Model access overview page. Some models do not require you to provide us case details (e.g. Amazon Titan or the models by Mistral) and are approved immediately. Others require you to fill out what you actually want to use the model for (e.g. Claude from Anthropic).
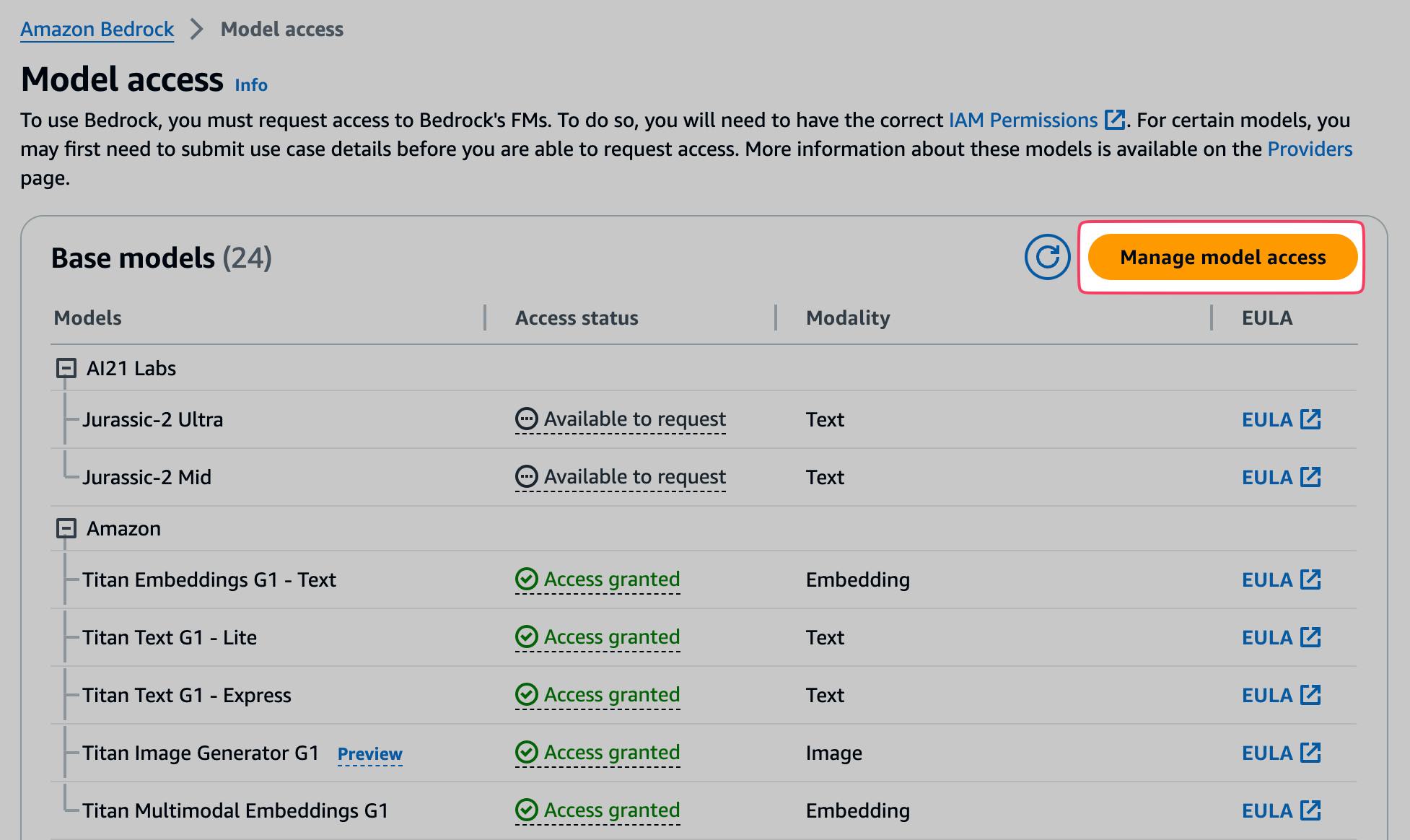
By clicking on Managed model access, you can check the necessary boxes for the models you want to use. For our example application, we'll work with the previously named models from Amazon, Mistral, and Anthropic. But feel free to request access to other models.
Once the request is granted, you'll see a green Access granted flag on the corresponding model.
Setting up Permissions for Our Functions
When we're working with Bedrock's models, we're solely charged for the usage that we generate. We don't have hourly costs just for requesting access to the models.
What we need to do so that our functions are able to access the Bedrock API is to set up the necessary IAM permissions. We've already seen this in our SST API definition previously, but let's do a quick recap:
We need:
bedrock:ListFoundationModelsto list the available models andbedrock:InvokeModelto actually submit prompts to a specific model
When we look into our function code that submits the prompts, we can see that we need slightly different payloads for the different models.
The general request structure always looks the same just the body differs based on the model provider:
import { InvokeModelCommand } from '@aws-sdk/client-bedrock-runtime';
const client = new BedrockRuntimeClient({ region: 'us-east-1' });
// [...]
new InvokeModelCommand({
modelId: model,
contentType: 'application/json',
accept: 'application/json',
body, // stringified JSON based on the model's requirements
});
The requirements of the models can be found in the AWS documentation. As an example, the Amazon Titan text models require the following body:
{
inputText: '\n\nUser: This is a test\n\nAssistant: ',
textGenerationConfig: {
temperature: 0.5,
topP: 1,
maxTokenCount: 300,
stopSequences: ['User:'],
},
}
In the inputText, we need to clarify which text is coming from us (prefixed with User: and which text was generated by the model (prefixed with Assistant: . This is required as we want to keep the context for the following messages (we'll always provide all of the previous messages in our requests).
Also, for each of the providers, we'll have a slightly difference response payload. For example, Amazon Titan will return the results in the response object in the path .results.[0].outputText while Claude from Anthropic will use .completion.
Speaking to the OpenAI API
Amazon Bedrock doesn't allow us to talk to the most famous model out there: GPT3.5 and GPT4. That's why we'll also integrate with the OpenAI API.
Setting up our API Key
As previously mentioned, for this we need to get access to the OpenAI API. For this, you'll have to apply at OpenAI, and once approved, obtain an API key that will allow you to make requests to the OpenAI API.
Once approved, you can generate a new API key in the API keys tab.
Since recently you'll also need to purchase credits in advance, as there's no invoice-based charging anymore. Nevertheless, if you're new to OpenAI, you'll most likely receive a few dollars in credits to get started for free.
Afterward, you'll need to provide the API key to SST:
npx sst secrets set OPENAI_API_KEY sk-Yj7...BBcZ
SST will then store your key securely at the parameter store of the Systems Manager service.
Forwarding our Prompts to OpenAI
Now, everything is already ready to go.
import OpenAI from 'openai';
import { Config } from 'sst/node/config';
import { ChatsEntity } from '../database/model/chats';
const DEFAULT_MODEL = 'gpt-3.5-turbo-0613';
export class OpenAiAdapter {
private client: OpenAI;
constructor() {
this.client = new OpenAI({ apiKey: Config.OPENAI_API_KEY });
}
// [...]
async submitPrompt(content: string, model = DEFAULT_MODEL): Promise<string> {
const chatCompletion = await this.client.chat.completions.create({
messages: [{ role: 'user', content }],
model,
stream: false,
});
return chatCompletion.choices[0].message.content!;
}
}
That's already it.
Building a Chat Interface
Let's build a simple but effective interface to interact with our models.
Designing our Interface
Our frontend will consist of two important pages: the notes and the chat view.
The Chat Interface is where we'll interact with the AI models. The chat interface should prominently feature an area for messages, an input field for typing new messages, and buttons for sending messages.
Messages from us and responses from the AI should be visually distinct.
From a function perspective we need to be able to:
View messages in a conversational format.
Enter new messages through a text input.
Send messages using a send button or by pressing "Enter".
Select between using Bedrock or OpenAI.
Select a model from one of the providers.
Clearing our previous messages to start a new chat.
So we'll end up with only two necessary routes:
/notesfor our note-taking view./chatfor our chat with our model.
Integrating Contextual Notes
The notes view is another essential part of our interface, allowing us to add, edit, and delete notes. These notes will be later used as contextual inputs in conversations with our AI models, simulating Retrieval-Augmented Generation (RAG) but without having our own (expensive) vector database.
What functions do we need? We should be able to:
Add new notes with a simple input form.
Edit existing notes directly within the interface.
Delete notes when they are no longer needed.
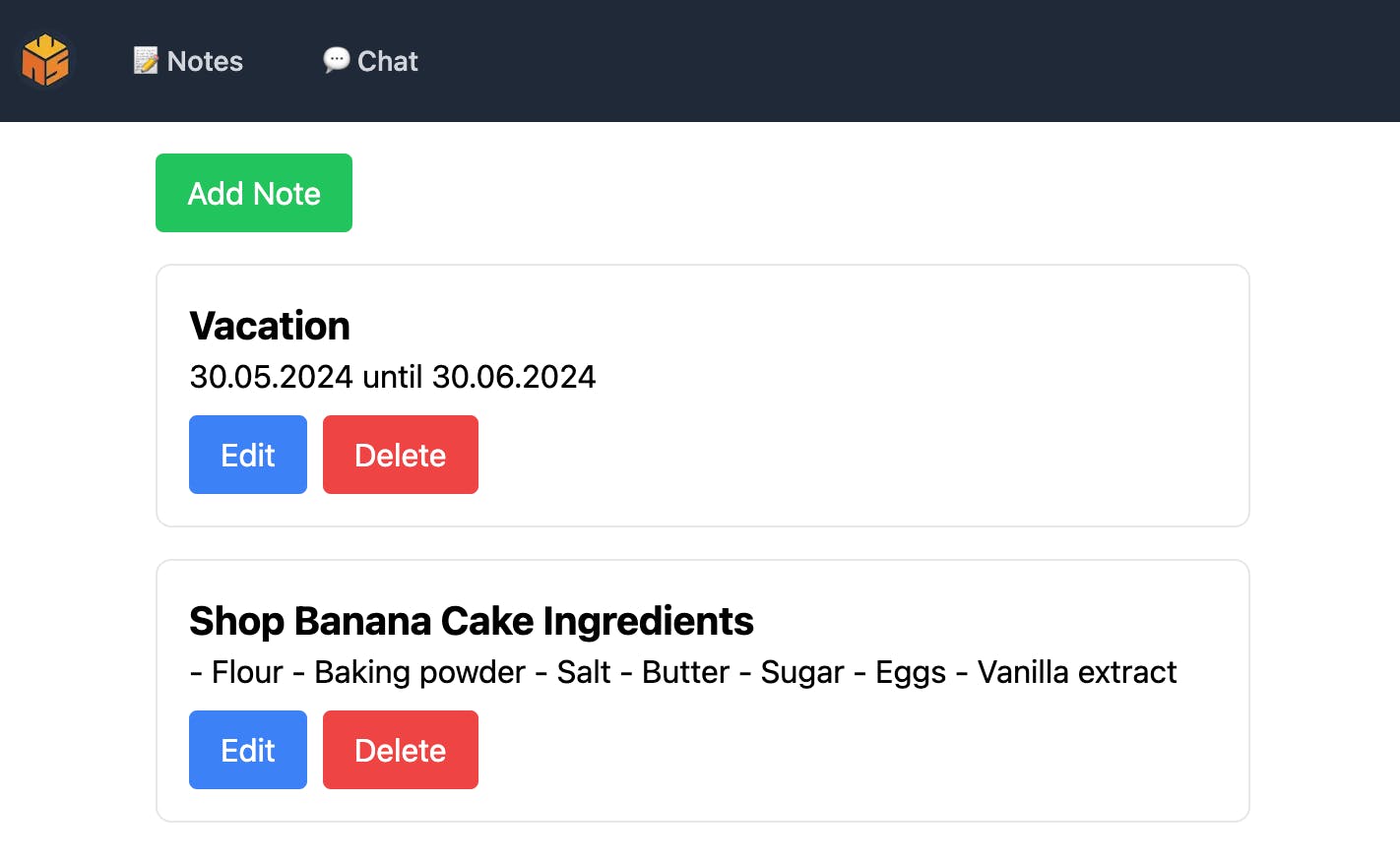
There we go. It's very simplistic but does what it should. 🎉
How Notes Are Used to Provide Context in Chats
We'll store all of our notes and chat messages in a DynamoDB table that we've created in one of the first steps of our journey.
function createTables(stack: Stack): Table[] {
const notes: Table = new Table(stack, 'notes', {
fields: {
id: 'string',
description: 'string',
text: 'string',
},
primaryIndex: { partitionKey: 'id' },
});
const chats: Table = new Table(stack, 'chats', {
fields: {
id: 'string',
},
primaryIndex: { partitionKey: 'id' },
});
return [notes, chats];
}
With this, we'll be able to keep our conversation even if we reload our window. We can also always add our notes to our chat prompts to ask contextual questions to our model.
We're doing this in a very simplistic approach: we're prefixing the start of our chat with the current state of our notes and providing the model a little bit of information on what this is and how it should be used.
These are some relevant notes I have taken.
Please only consider using this information if it seems useful for the questions that I ask you.
DO NOT CONFIRM THAT you understood this.
Continue with our chat as if I never provided any additional information in the first place:
{notes}
Surely, this can be fine-tuned for exceeding use cases, but it already does a pretty good job with models like Amazon Titan or OpenAI's GPT4.
Testing our Application
Let's create a few notes and test our chat with different models.

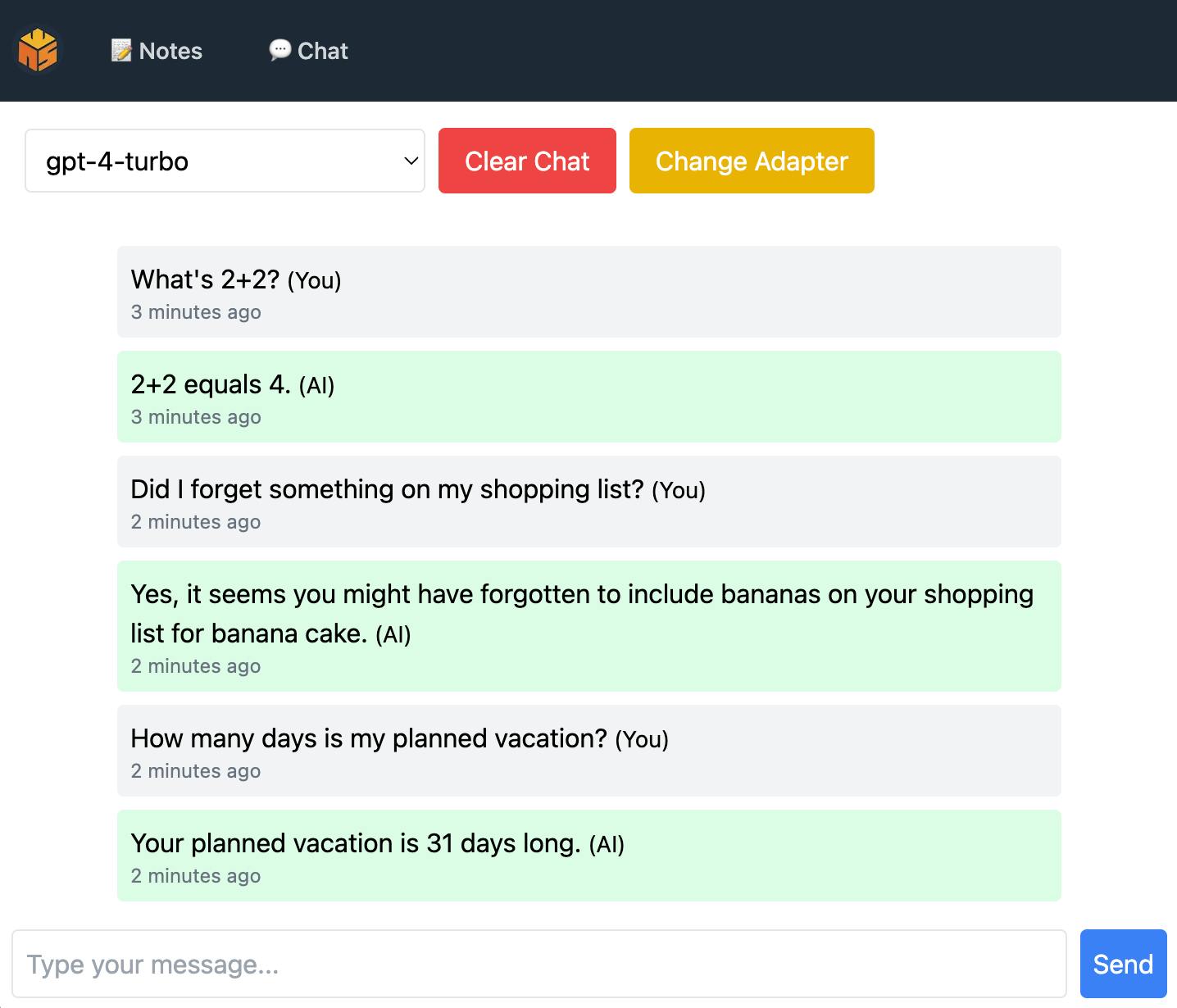
As seen, 'context-less' questions are answered without issues.
Additionally, the model receives our notes so it's able to answer questions related to our notes.
Where to Go from Here
The completion of this serverless chat application marks just the beginning of what can be an expansive project with numerous potential enhancements and features.
There are several ways you can expand this application to increase its capabilities:
Expanding Chat Functionality
Multiple Chats in Parallel: Enhance the application to support handling multiple chat sessions simultaneously. This could involve extending the backend to manage different chat threads and updating the frontend to switch between active chats.
Support for More Models: Although currently integrated with Amazon Bedrock and OpenAI, the application can be extended to support additional models from these or other AI platforms.
Dynamic Model Configuration: Implement UI elements that allow you to configure model parameters dynamically, such as the response length, temperature, and other model-specific settings. This would help to tailor the AI responses custom preferences, making the interactions more flexible and personalized.
Since this project is open source, we're happy to welcome contributions.
Whether it's refining the existing features, adding new functionalities, or improving the interface, every contribution plays a significant role. ✌️